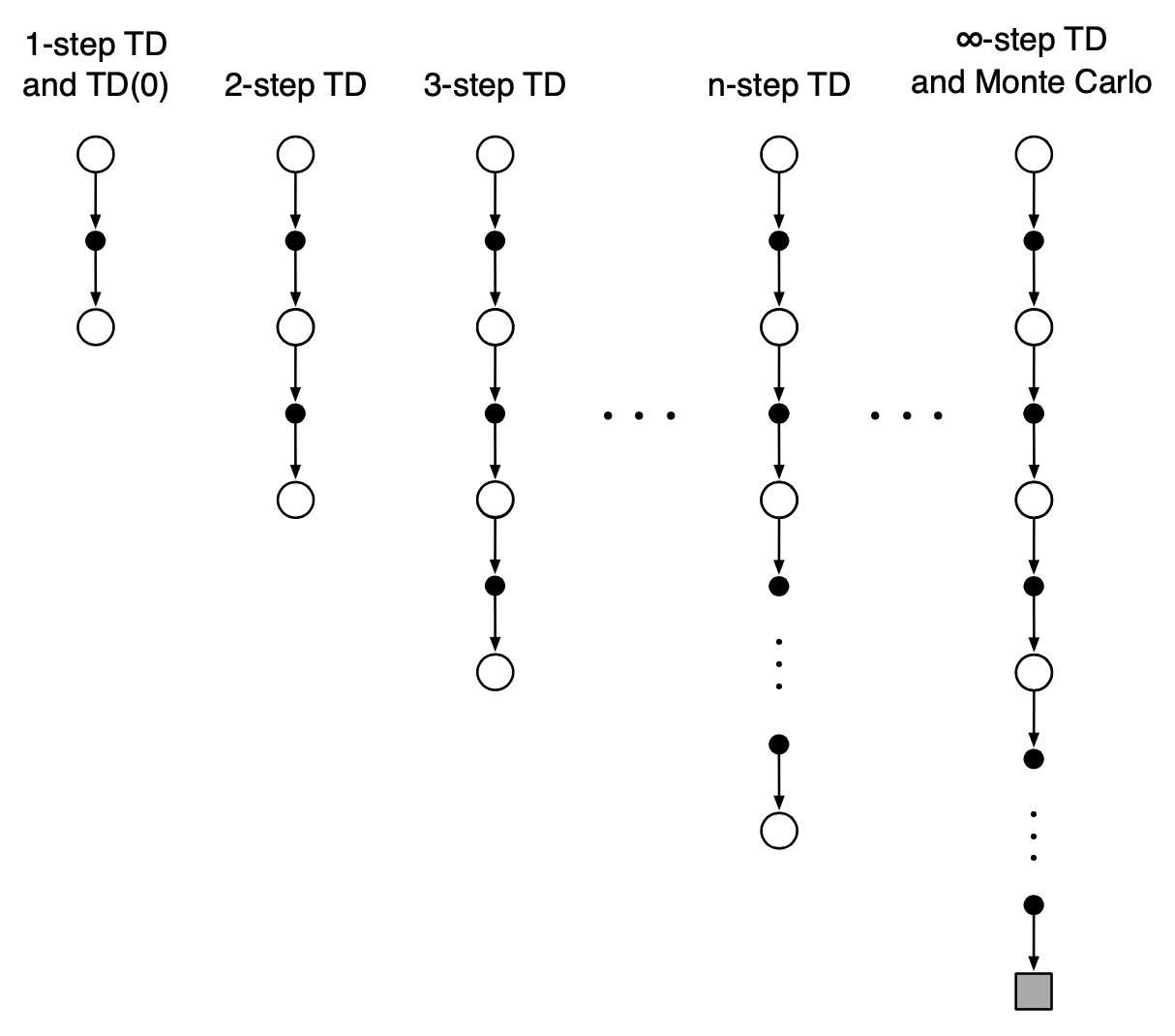
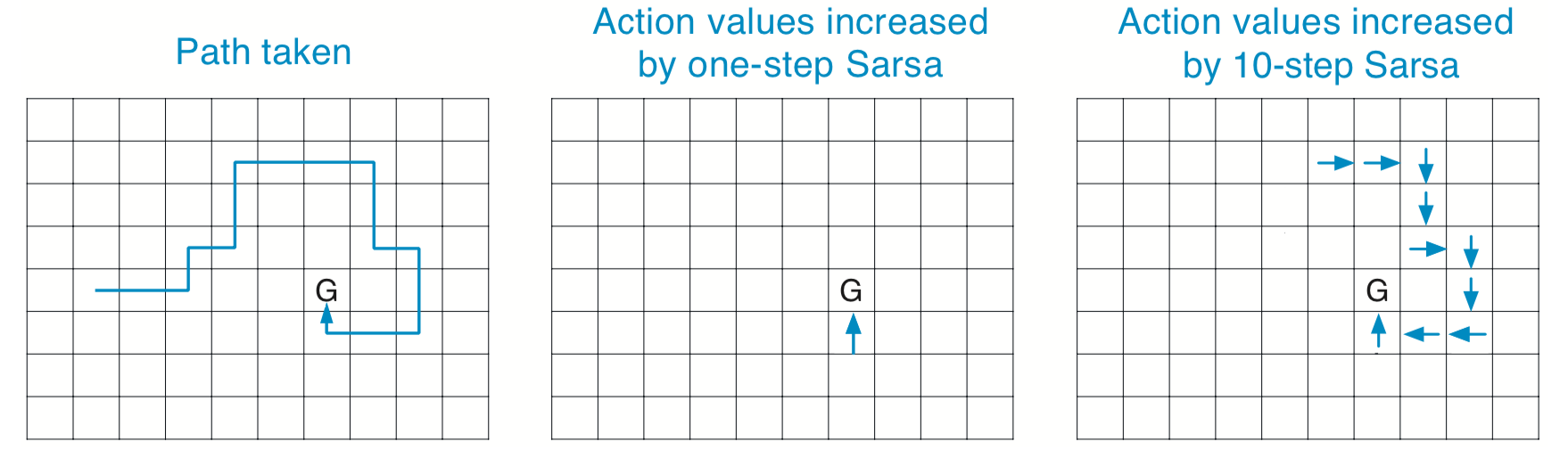
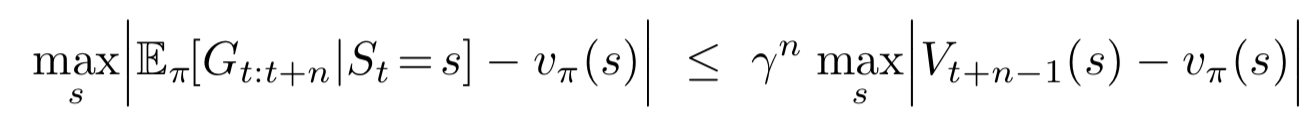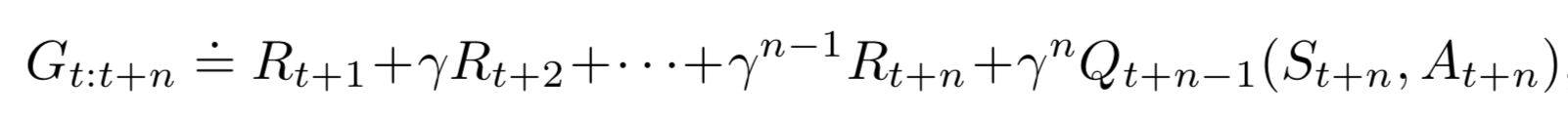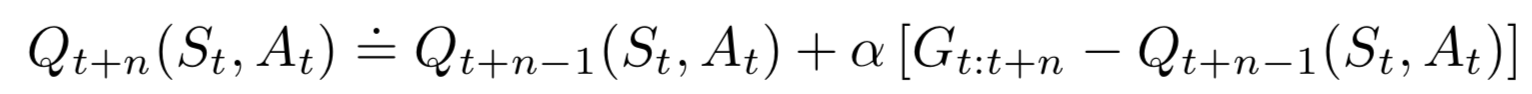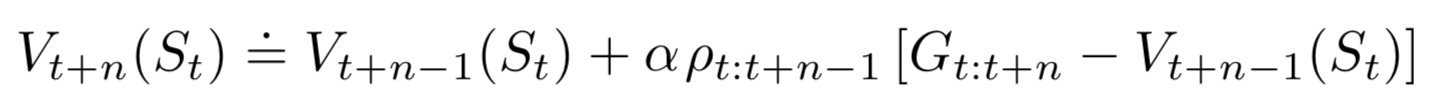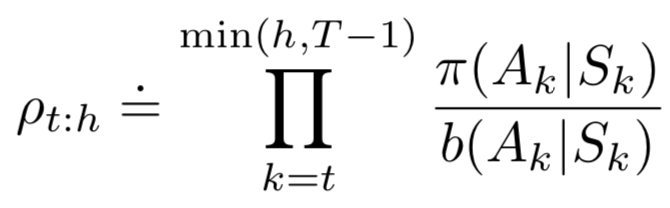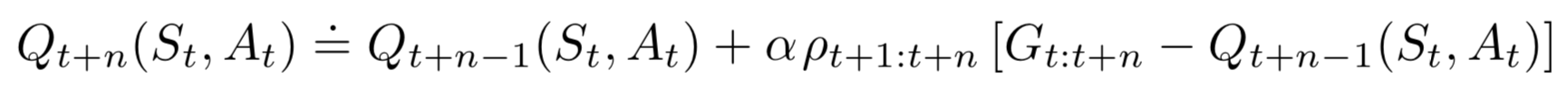\(n\)-step TD Prediction
![]()
Monte Carlo Target
\[
\begin{align}
G_t &= R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots + \gamma^{T-t-1} R_{T} \\
V(S_t) &= V(S_t) + \alpha [G_t - V(S_t)]
\end{align}
\]
One-Step TD target
\[
\begin{align}
G_{t:t+1} &= R_{t+1} + \gamma V(S_{t+1}) \\
V(S_t) &= V(S_t) + \alpha [G_{t:t+1} - V(S_t)]
\end{align}
\]
\(V(S_{t+1})\) used as a surrogate for returns following \(S_{t+1}\)
Two-Step TD target
\[
\begin{align}
G_{t:t+2} &= R_{t+1} + \gamma R_{t+2} + \gamma^2 V(S_{t+2}) \\
V(S_t) &= V(S_t) + \alpha [G_{t:t+2} - V(S_t)]
\end{align}
\]
\(V(S_{t+2})\) used as a surrogate for returns following \(S_{t+2}\)
\(n\)-Step TD target
\[
\begin{align}
G_{t:t+n} &= R_{t+1} + \gamma R_{t+2} + \cdots + \gamma^{n-1} R_{t+n} + \gamma^{n} V(S_{t+n}) \\
V(S_t) &= V(S_t) + \alpha [G_{t:t+n} - V(S_t)]
\end{align}
\]
\(V(S_{t+n})\) used as a surrogate for returns following \(S_{t+n}\)
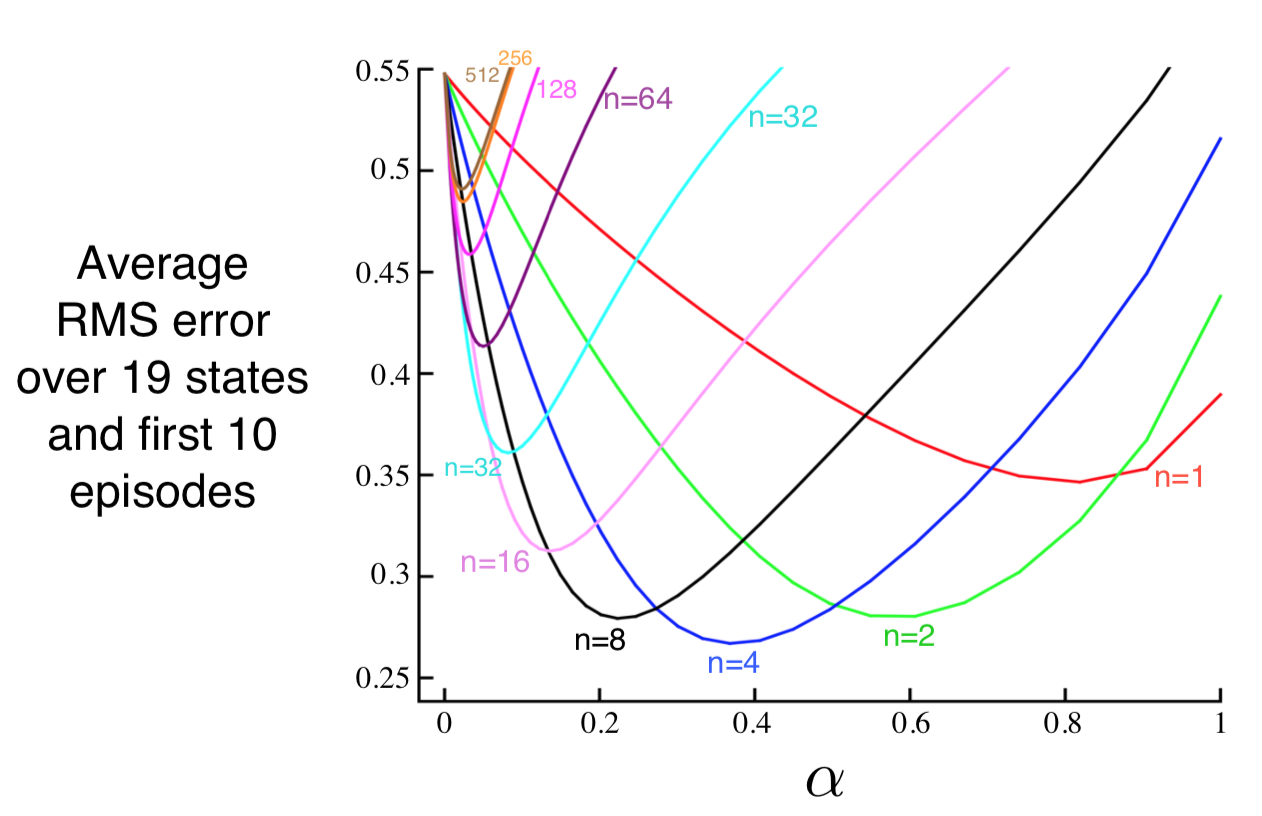
Algorithm
![]()
Error Reduction Property
![]()
Guarantees that \(n\)-step TD methods converge to \(v_\pi\)
One-step TD and MC methods are special cases