Chapter 6: Temporal-Difference Learning
2019/13/12
TD Prediction Algorithm

TD(0) Backup Diagram
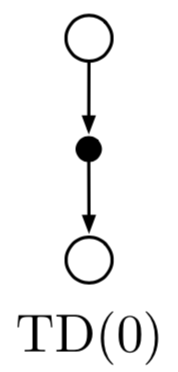
- TD and MC use sample updates
- DP uses expected updates
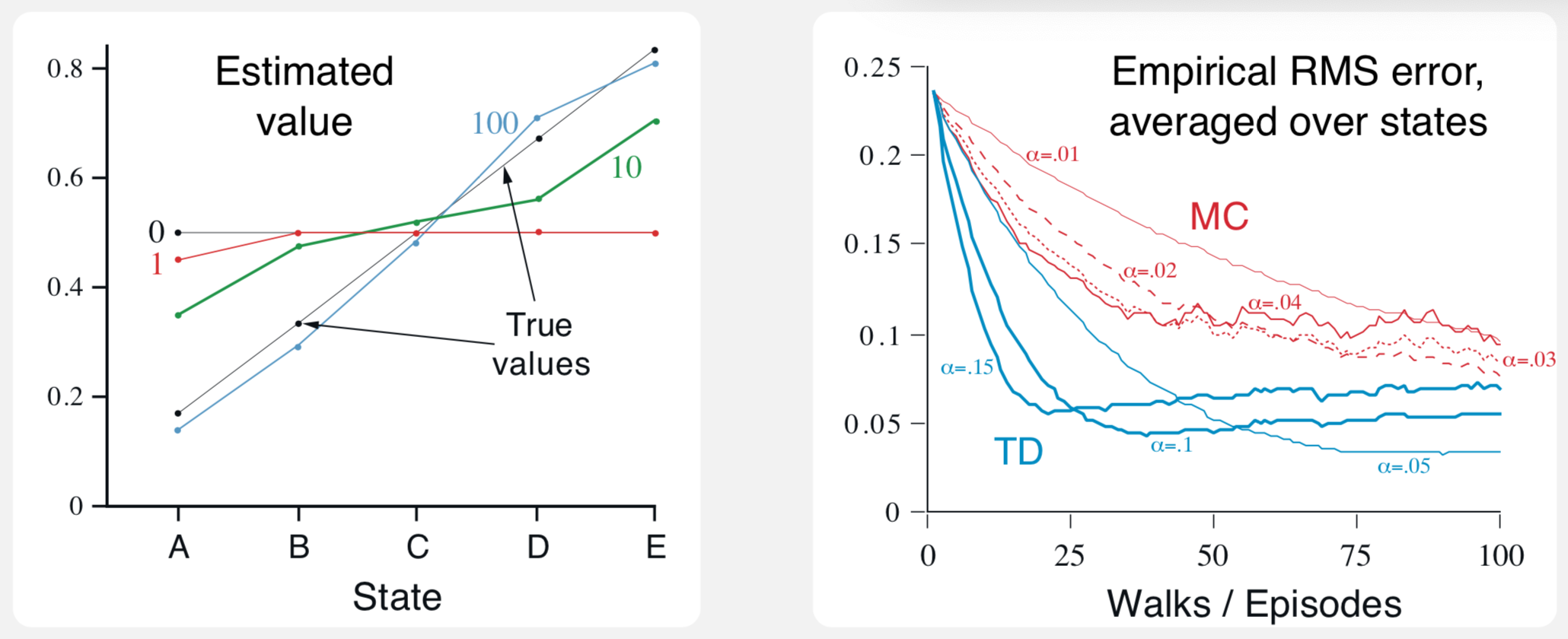
Example 6.2 Random Walk
Homework: Do exercises 6.3 and 6.4 and 6.6.
Example 6.3 Random Walk
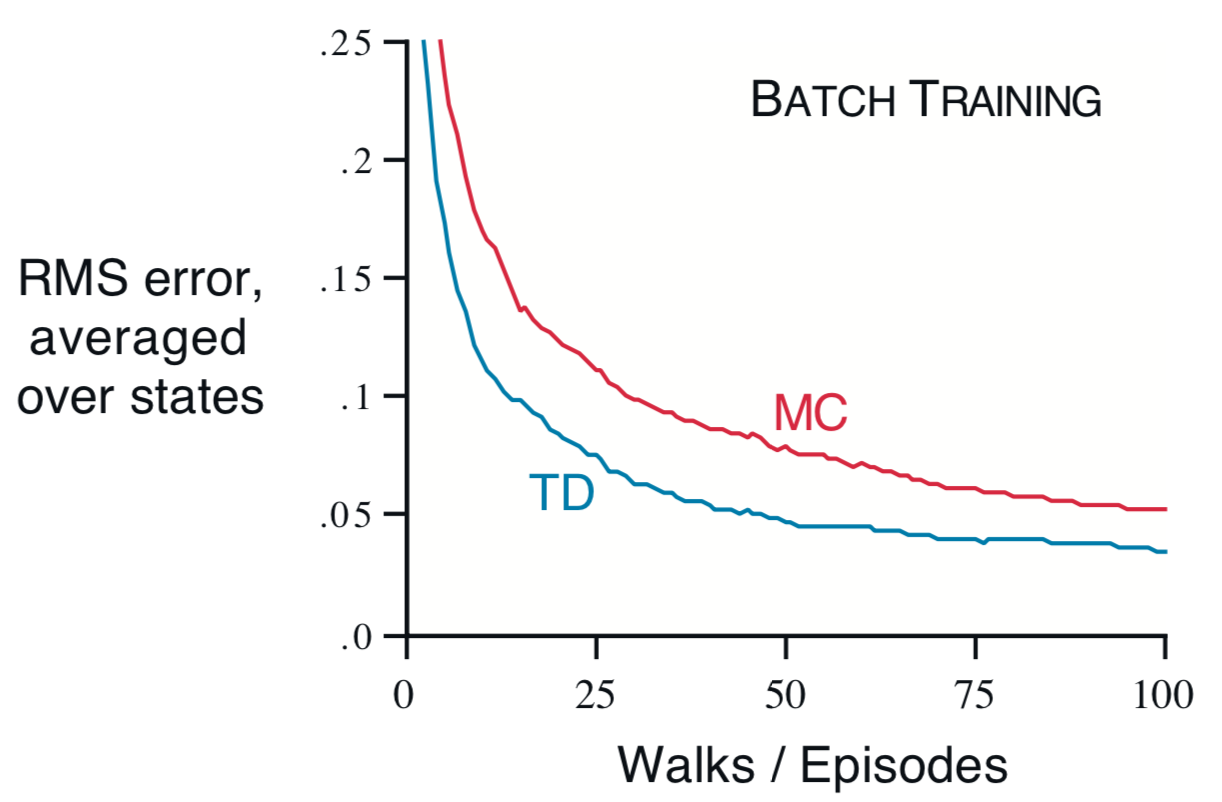
- MC averages actual returns and is optimal (minimizes MSE)
- How does TD perform better?
- TD is optimal in a way that is more relevant to predicting returns
Episode
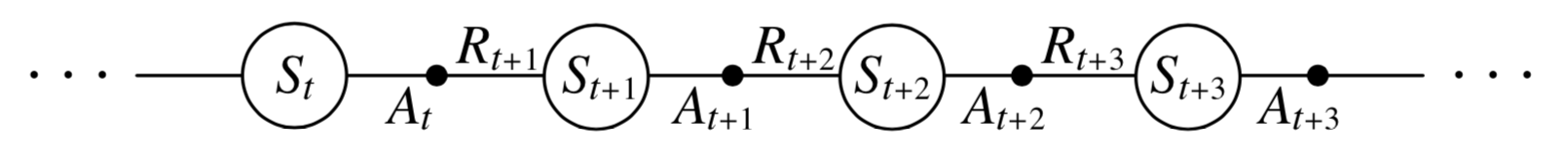
- Previously considered \(s \rightarrow s'\) transitions and learned value \(v_\pi(s)\) of states
- Now consider \((s,a) \rightarrow (s',a')\) transitions and learn value \(q_\pi(s,a)\) of state-action pairs
SARSA Backup Diagram
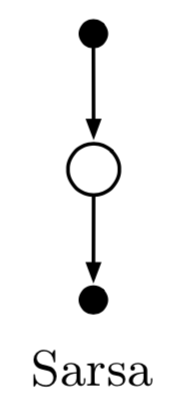
?

Example 6.5 Windy Gridworld
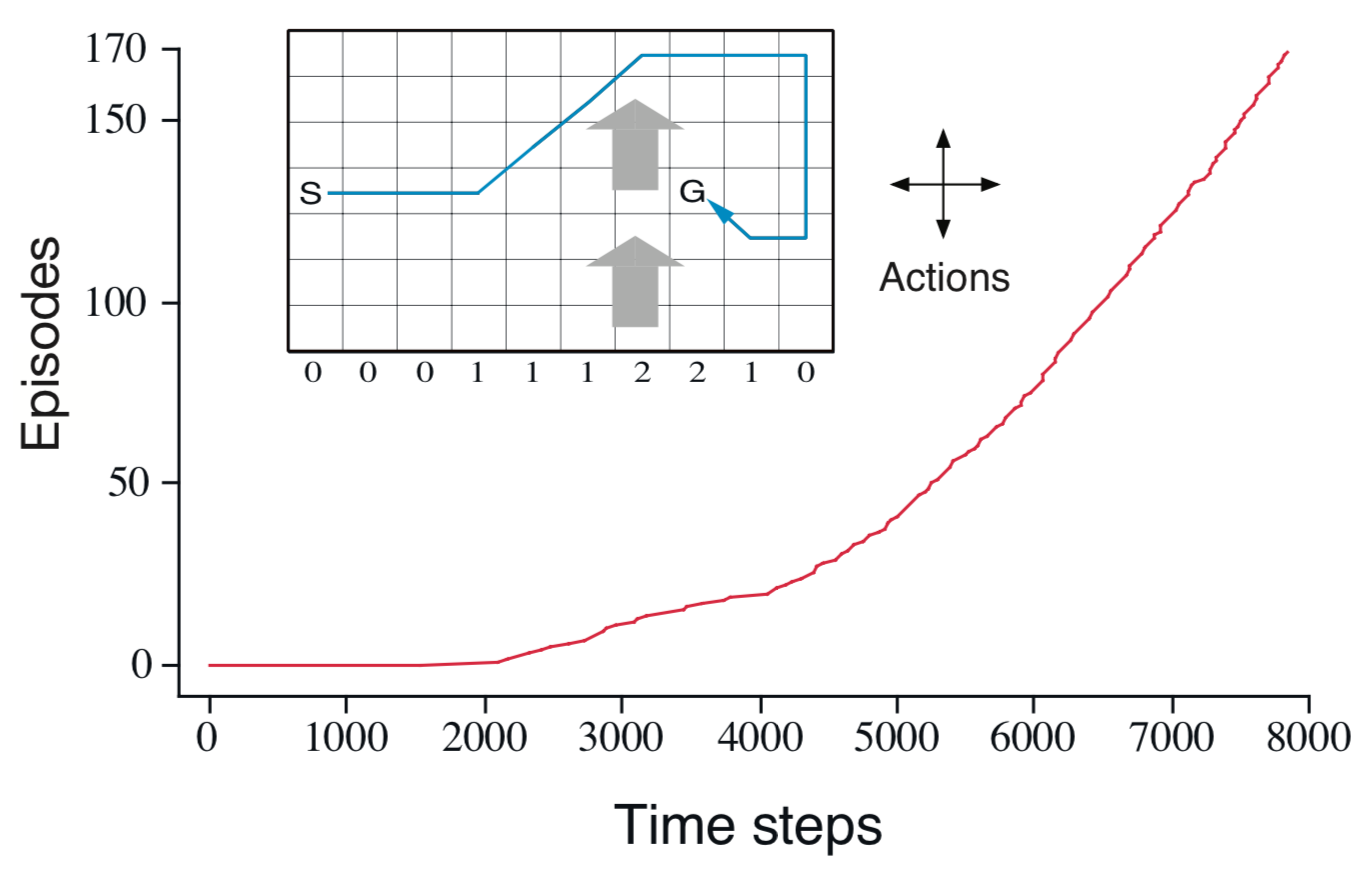
- Discuss example and performance curve
- How can MC fail for this problem?
- See code here
Q-Learning Algorithm

Why is this considered off-policy?
Backup Diagrams

Comparison

Q-Learning is Max. Biased

Why does Q-learning choose left (wrong choice)?
Double Learning Algorithm

Tic-Tac-Toe
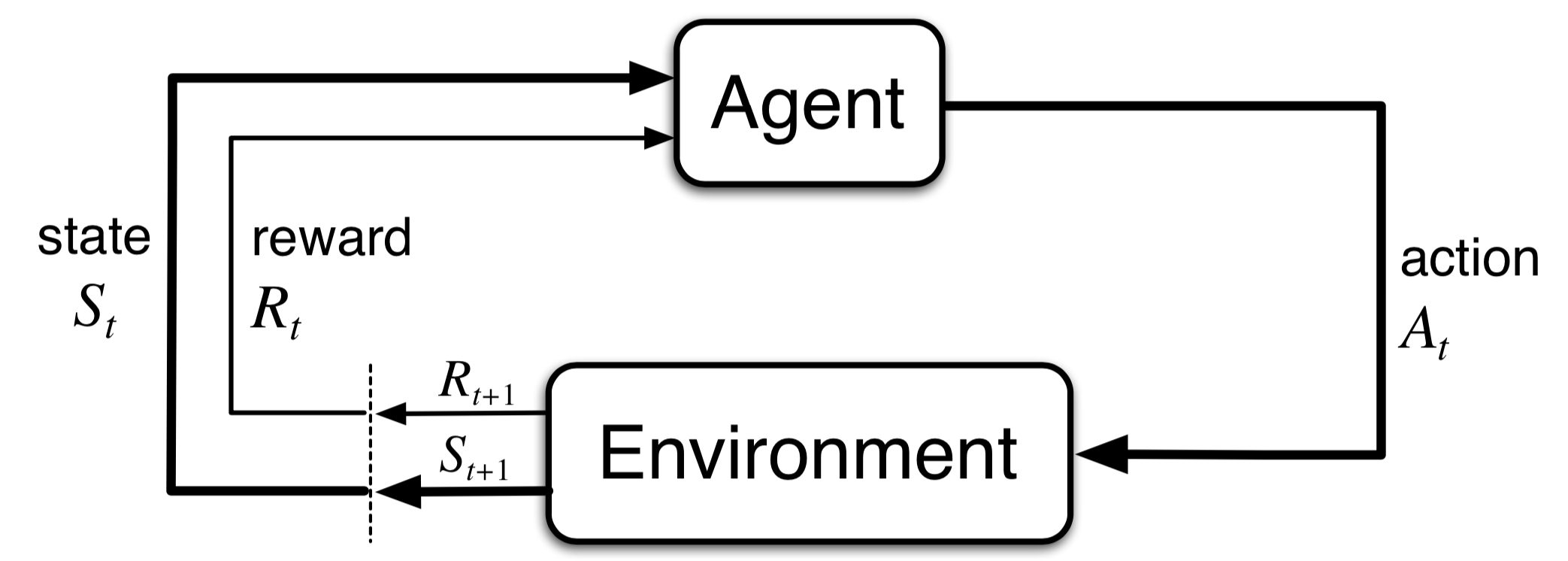
- Discuss tic-tac-toe in the agent-environment setting
- Discuss state vs. “afterstate”
- Discuss state-action vs. position-move
- Why is afterstate-value more efficient than action-value?