Exercises
- Give an equation for \(v_\pi\) in terms of \(q_\pi\) and \(\pi\) (solution)
- Given an equation for \(q_\pi\) in terms of \(v_\pi\) and four-argument \(p\) (solution)
Answers
\[
\begin{align}
v_\pi(s) &= \sum_a q_\pi(s,a) \pi (s|a)\\
q_\pi(s,a) &= \sum_{s'} \sum_r \left[ r + \gamma v_\pi(s') \right]p(s',r|s,a)
\end{align}
\]
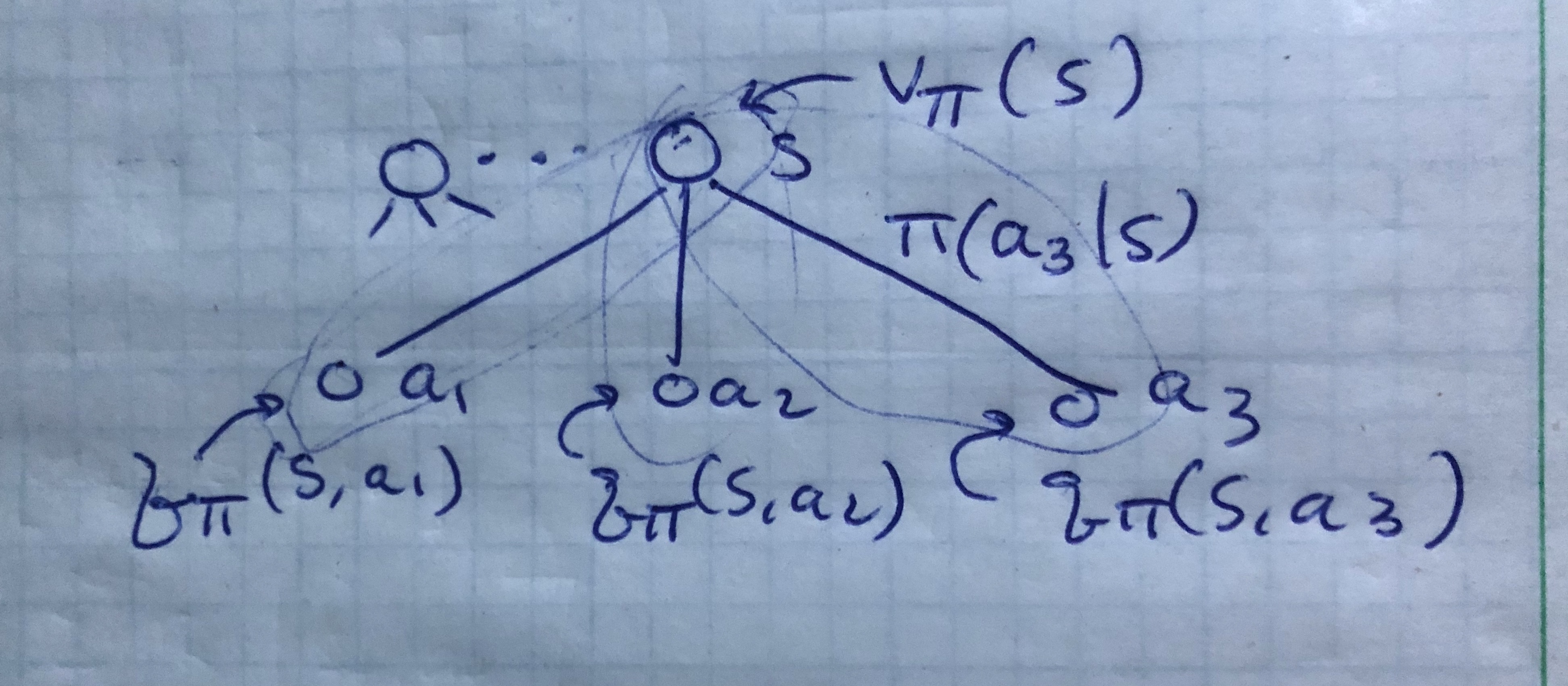
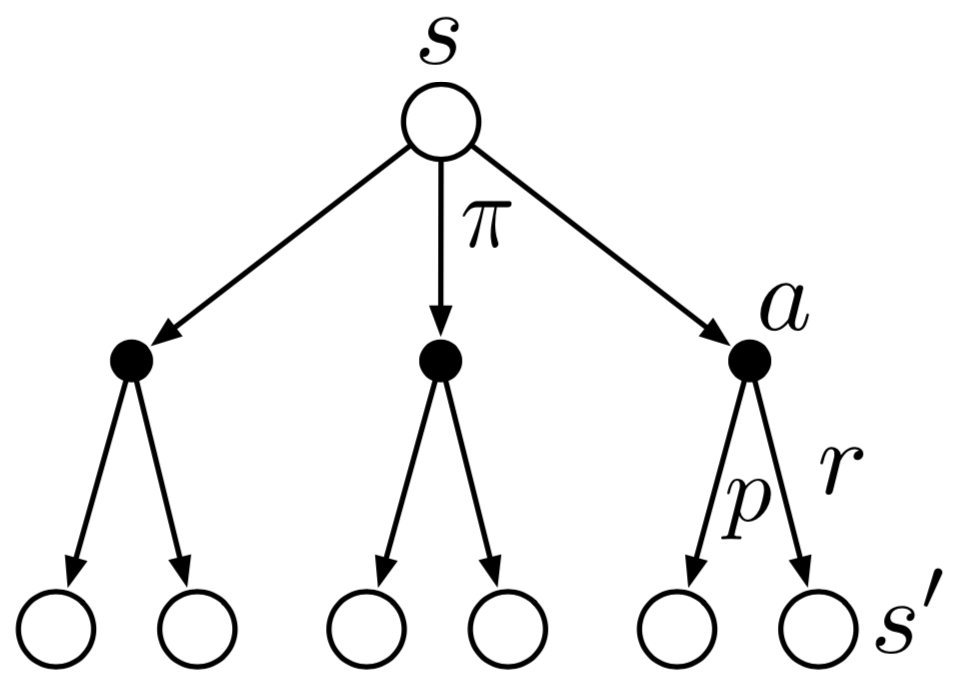
Backup Diagram for \(v_\pi\)
\[
v_\pi(s) = \sum_a q_\pi(s,a) \pi (s|a)
\]
![]()
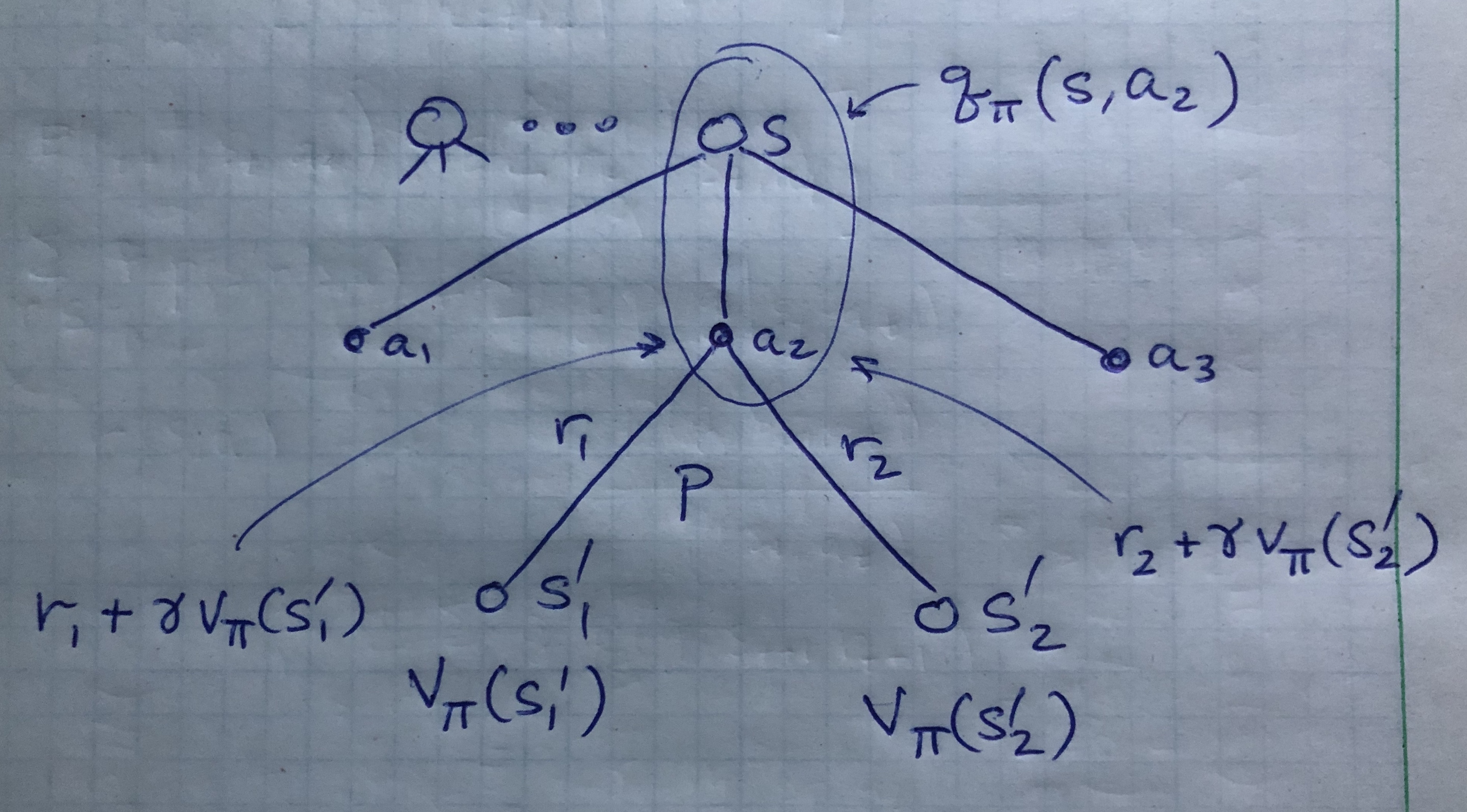
Backup Diagram for \(q_\pi\)
\[
q_\pi(s,a) = \sum_{s'} \sum_r \left[ r + \gamma v_\pi(s') \right]p(s',r|s,a)
\]
![]()
Value Recursion
Substitute \(v_\pi\)-\(q_\pi\) relations into one another to obtain recursions.
\[
\begin{align}
v_\pi(s) &= \sum_a \pi(a|s) \sum_{s',r}
\left[ r + \gamma v_\pi(s') \right]p(s',r|s,a) \\
q_\pi(s,a) &= \sum_{s',r} \left[ r + \gamma \sum_{a'} q_\pi(s',a') \pi(s'|a') \right]p(s',r|s,a)
\end{align}
\]
State-Value Recursion
\[
v_\pi(s) = \sum_a \pi(a|s) \sum_{s',r}
\left[ r + \gamma v_\pi(s') \right]p(s',r|s,a)
\]
- Consistency condition between \(v_\pi(s)\) and \(v_\pi(s')\)
- Expected value of \(r+\gamma v_\pi(s')\) over \(p(s',r,a|s) = \pi(a|s)p(s',r|s,a)\)
- Bellman equation for \(v_\pi\)
- \(v_\pi\) is unique solution to Bellman equation
- Bellman equation: Compute, approximate, learn \(v_\pi\)
Backup Diagram for \(v_\pi\)
Graphical representation of \(v_\pi\) recursion from \(s'\) to \(s\)
- Start state \(s\) at top (open circle)
- Policy \(\pi\) gives action \(a\) (solid circle)
- Environment responds with reward \(r\) and next state \(s'\) according to probability \(p\)
Optimal Policies
- Value function defines a partial order for policies
\[
\pi \geq \pi' \quad \Leftrightarrow \quad v_\pi(s) \geq v_{\pi'}(s)
\;\;\forall\;\;s \in \mathcal{S}
\]
- An optimal policy exists but may not be unique
- Denote optimal policies by \(\pi_\ast\)
- Denote optimal state-value function \(v_\ast = v_{\pi_\ast}\)
Optimal Policies
\[
\begin{align}
v_\ast(s) &= \max_\pi v_\pi(s) \;\;\forall\;\;s\in\mathcal{S} \\
q_\ast(s,a) &= \max_\pi q_\pi(s,a) \;\;\forall\;\;s\in\mathcal{S}
\;\;\text{and}\;\; a\in\mathcal{A}(s)
\end{align}
\]
- The same policy optimizes both value functions
Relations
- Q: What does the optimal policy \(\pi_\ast\) look like?
- A: It puts all its weight on the best action (greed)
\[
\begin{gather}
\pi_\ast(a|s) = \mathbb{1}_{a=a_\ast} = \begin{cases}
1, & a=a_\ast \\ 0, & \text{otherwise} \end{cases} \\[1em]
v_\ast(s) = \sum_{a\in\mathcal{A}(s)} \pi_\ast(a|s)
q_\ast(s,a) = \max_{a\in\mathcal{A}(s)} q_\ast(s,a)
\end{gather}
\]
Recursion for Optimal Value Function
Leveraging this derivation and \(\pi=\pi_\ast\), we have
\[
\begin{align}
v_\ast(s) &= \max_a q_\ast(s,a) \\
&= \max_a E[R_{t+1} + \gamma G_{t+1} | S_t=s,A_t=a] \\
&= \max_a E[R_{t+1} + \gamma v_\ast(S_{t+1}) | S_t=s, A_t=a] \\
&= \max_a \sum_{s',r} p(s',r|s,a) [r + \gamma v_\ast(s')]
\end{align}
\]
Apply Greed
\[
\begin{align}
v_\pi(s) &= \sum_a \pi(a|s) \sum_{s',r}
\left[ r + \gamma v_\pi(s') \right]p(s',r|s,a) \\
v_\ast(s) &= \max_a \sum_{s',r}
\left[ r + \gamma v_\ast(s') \right]p(s',r|s,a)
\end{align}
\]
\[
\sum_a \pi_\ast(a|s) \quad \overset{\text{greed}}{\longrightarrow} \quad \max_a
\]
Recursion for Optimal Action-Value Function
Applying greed, we have
\[
\begin{align}
q_\pi(s,a) &= \sum_{s',r} p(s',r|s,a) \left[ r + \gamma \sum_{a'} \pi(s'|a') q_\pi(s',a') \right] \\
q_\ast(s,a) &= \sum_{s',r} p(s',r|s,a)\left[ r + \gamma \max_{a'} q_\ast(s',a') \right]
\end{align}
\]
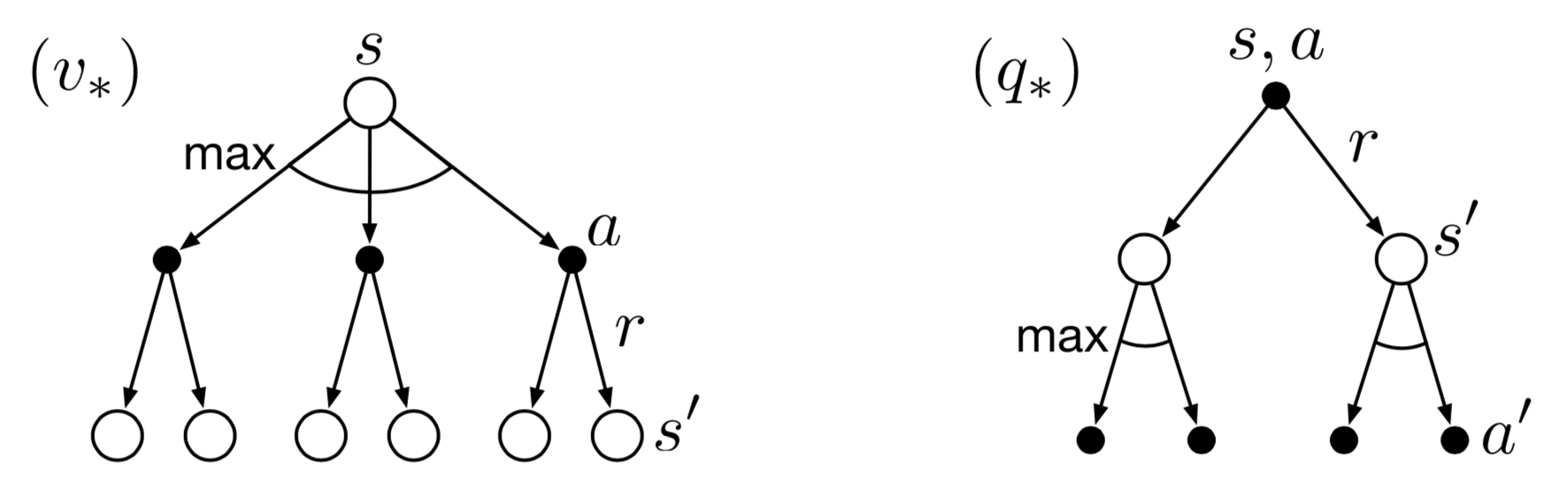
Backup Diagrams for Optimal Value Functions
![]()
Optimal Policy for Gridworld
![]()
(We don’t yet know how to find \(v_\ast\). Take this as given for now.)
Optimal Policy \(\leftarrow\) Optimal Value
- Given \(v_\ast(s)\), \(\pi_\ast(a|s)\) assigns non-zero probability to best action(s) and zero probability to all other actions
- Optimal policy \(\pi_\ast\) is greedy wrt optimal value \(v_\ast\)
- A one-step (short-run) search is long-run optimal
- \(v_\ast\) “takes into account the reward consequences of all possible future behavior”
- Expected long-term return is encoded into \(v_\ast\)
Optimal Policy \(\leftarrow\) Optimal Value
- Same for \(q_\ast(s,a)\) … in any state \(s\), choose the best action \(a\)
- Costs more to store \(q_\ast(s,a)\) than \(v_\ast(s)\)
- \(q_\ast\) encodes best action(s) without needing to know values of next states or environment dynamics \(p(s',r|s,a)\)
Bellman’s Eqations in Practice
\[
\begin{align}
v_\ast(s) &= \max_a \sum_{s',r}
\left[ r + \gamma v_\ast(s') \right]p(s',r|s,a) \\
q_\ast(s,a) &= \sum_{s',r} p(s',r|s,a)\left[ r + \gamma \max_{a'} q_\ast(s',a') \right]
\end{align}
\]
- Usually don’t know \(p(s',r|s,a)\)
- Usually can’t compute (sum and max too big)
- Markov property (assume this)