Why GPUs?
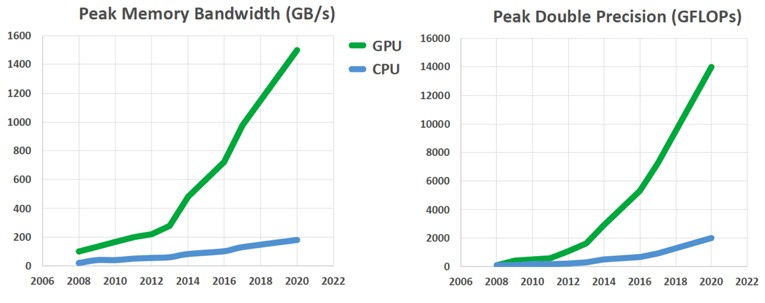
Exploit course-grained and fine-grained parallelism.
GPUs can be faster than CPUs, but they can be slower too. Results depend on the code you write.
Outline
Definitions
GPU hardware: streaming multiprocessors (SM) and memory model
Grids, blocks, threads, warps
CUDA programming concepts
Example programs
CUDA programming model basics
Heterogeneous programming model: CPU and GPU
Host = CPU and its memory
Device = GPU and its memory
Host manages memory on: host and device
Host calls functions that run on: host and device
Kernel is a device function
Launch a kernel means call a device function
Device functions can call other device functions
Kernels are executed in parallel in many threads on the device - Single Instruction, Multiple Threads (SIMT)
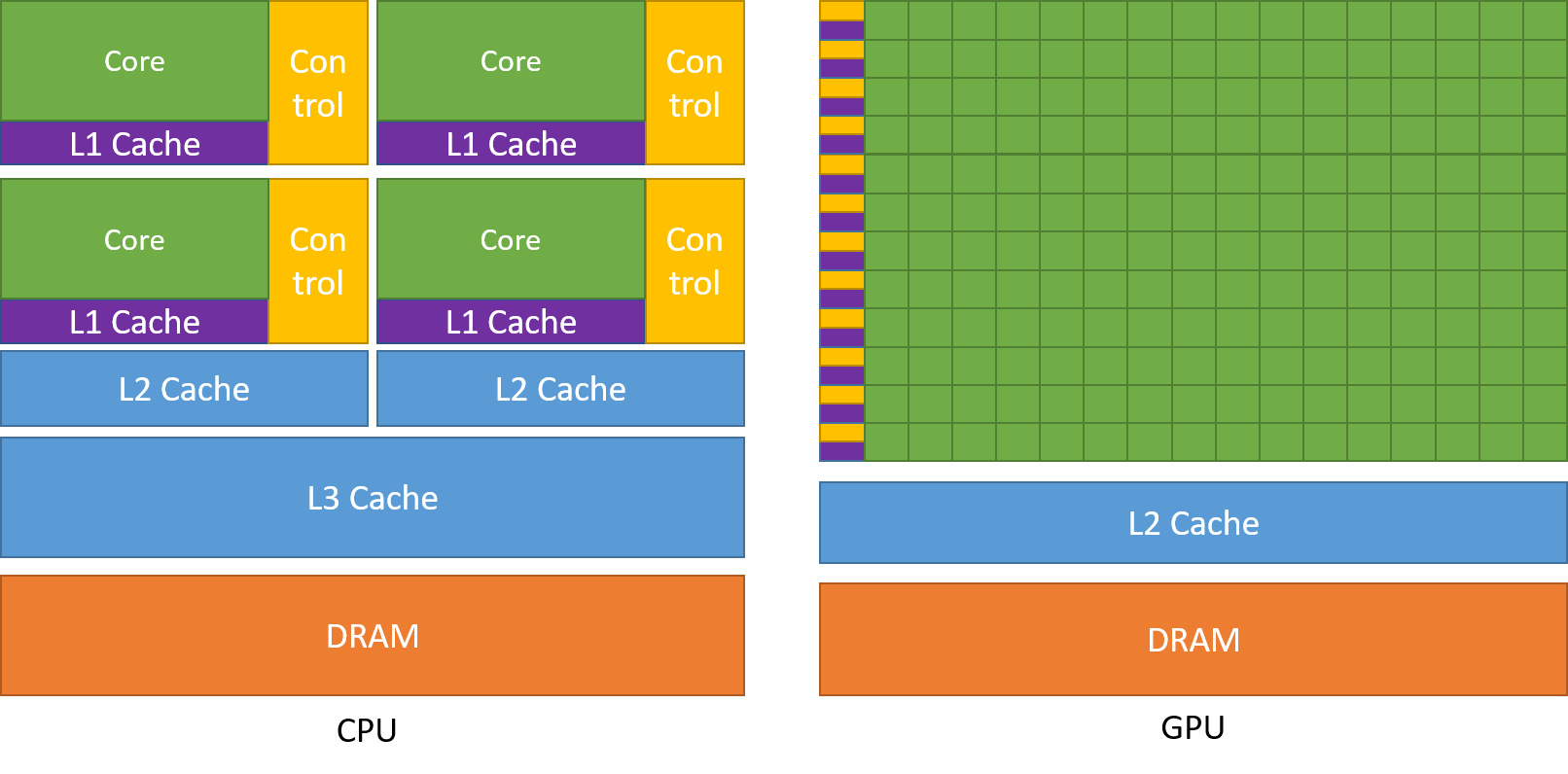
Key CUDA abstractions
Hierarchy of thread groups
Shared memories
Barrier synchronization
These are exposed to the programmer through a minimal set of language abstractions.
Partition problem into course sub-problems that can be solved independently in parallel by blocks of threads. (Blocks are independent and parallel.)
Partition sub-problems into finer pieces that can be solved cooperatively in parallel by all threads within a block. (Threads work together and in parallel.)
GPU hardware examples
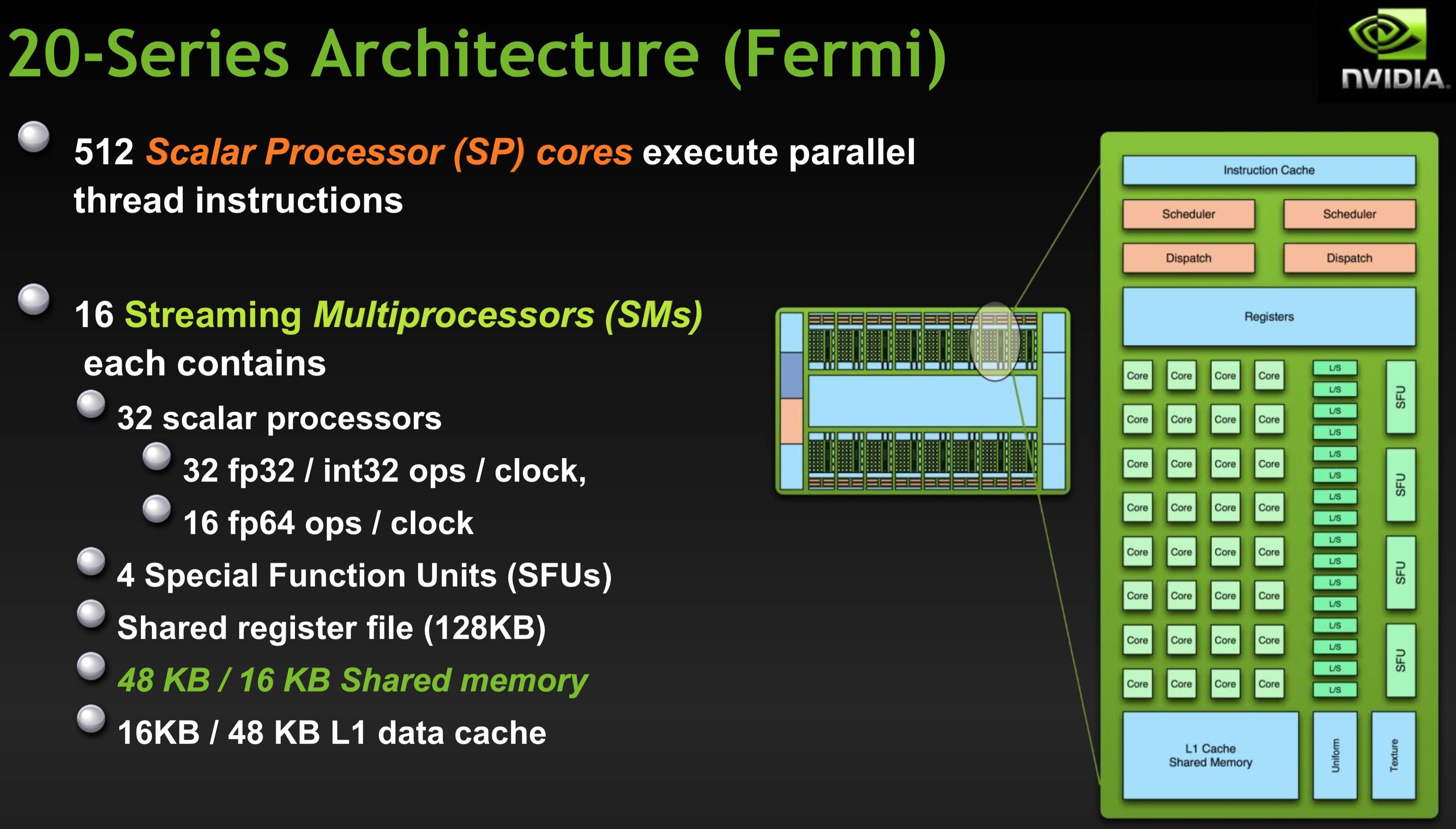
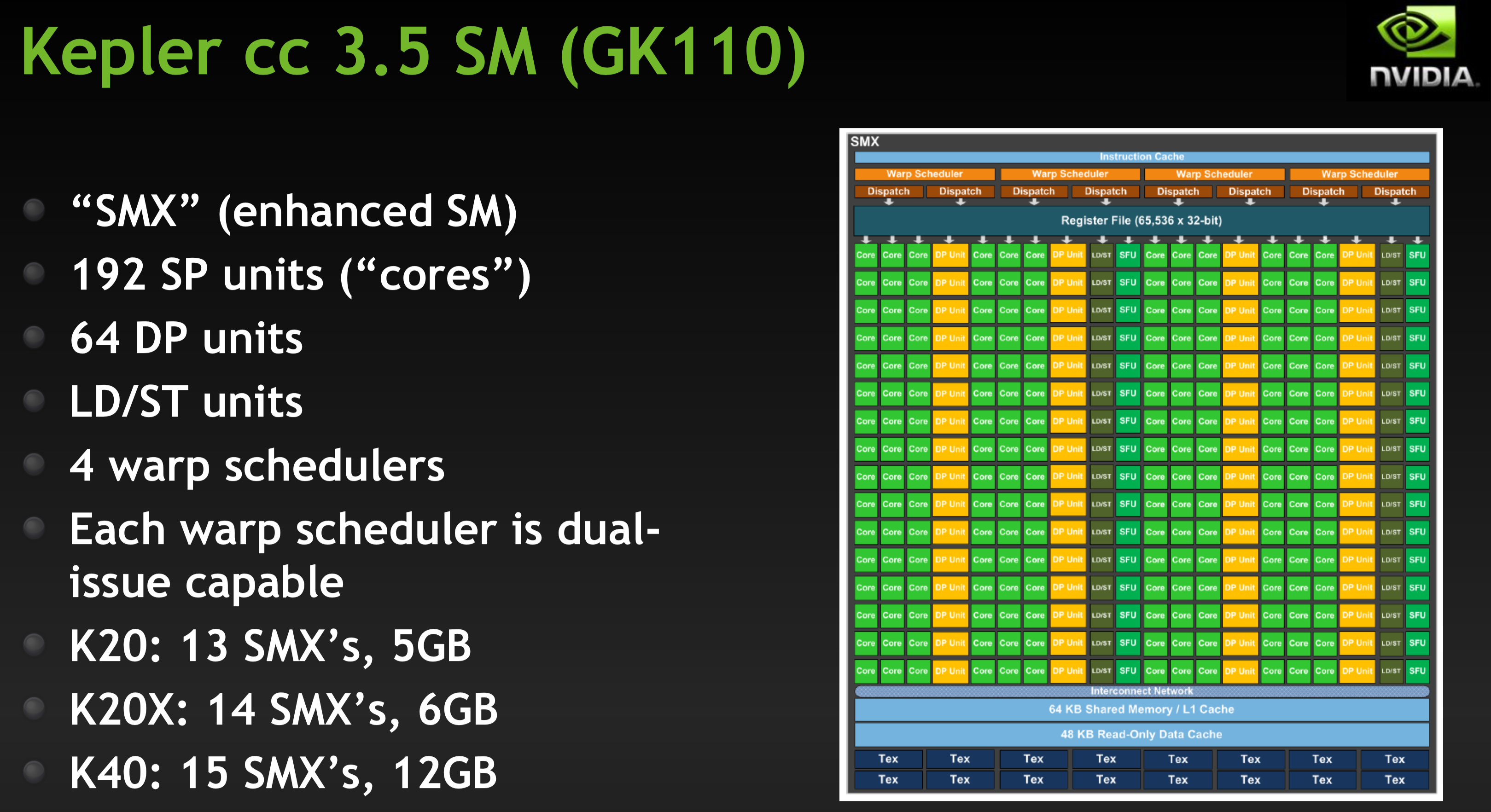
The Nvidia Jetson TX2 we will be using in our lab is based on the "Pascal" architecture. It has 2 SMs with 128 cores/SM. A stand-alone GPU based on Pascal:

Modern GPUs include hardware for special instructions (sine, cosine, etc.), as well as single and double precision floating-point units.
GPU software/hardware

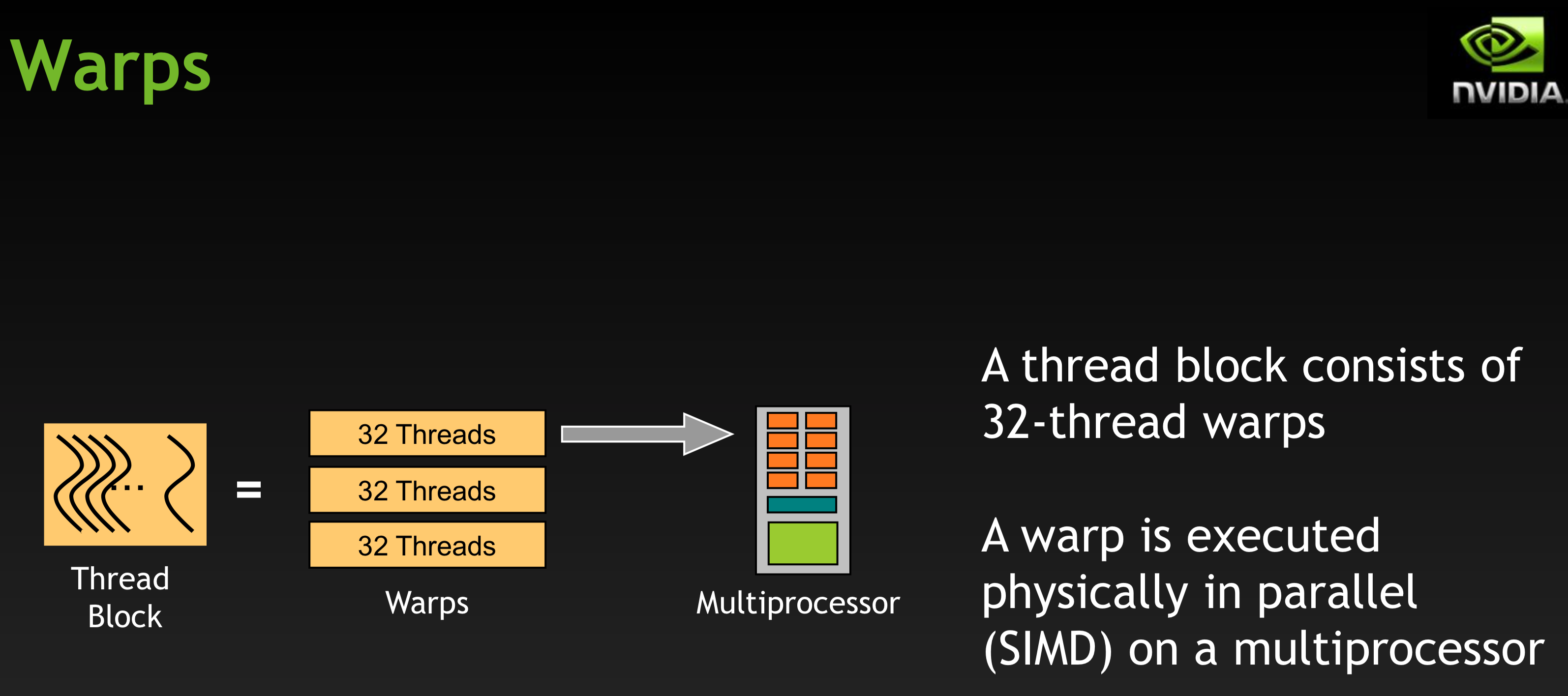
Typically number of threads per block should be multiple of 32 (128 and 256 are typical).
SM can concurrently execute up to 8 thread blocks.
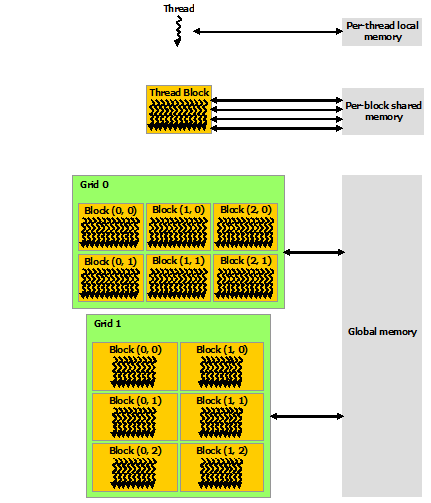
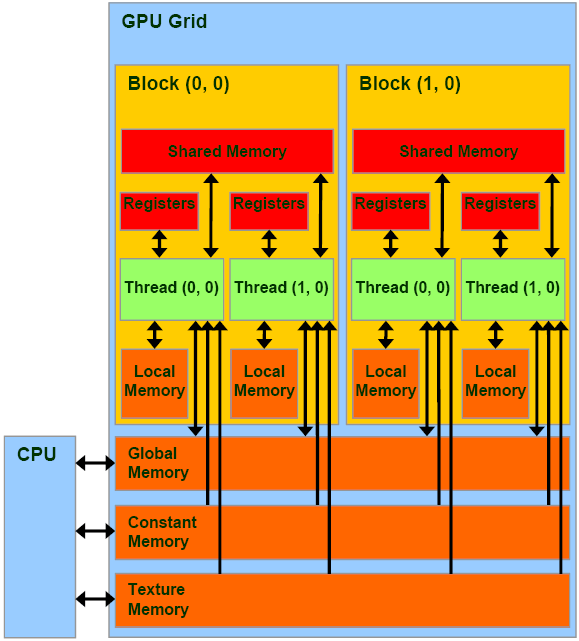
GPU memory model
There are different types of memory in the memory hierarchy, with different accessibility. The following is a programming hierarchy.
The physical memory is designed as follows.
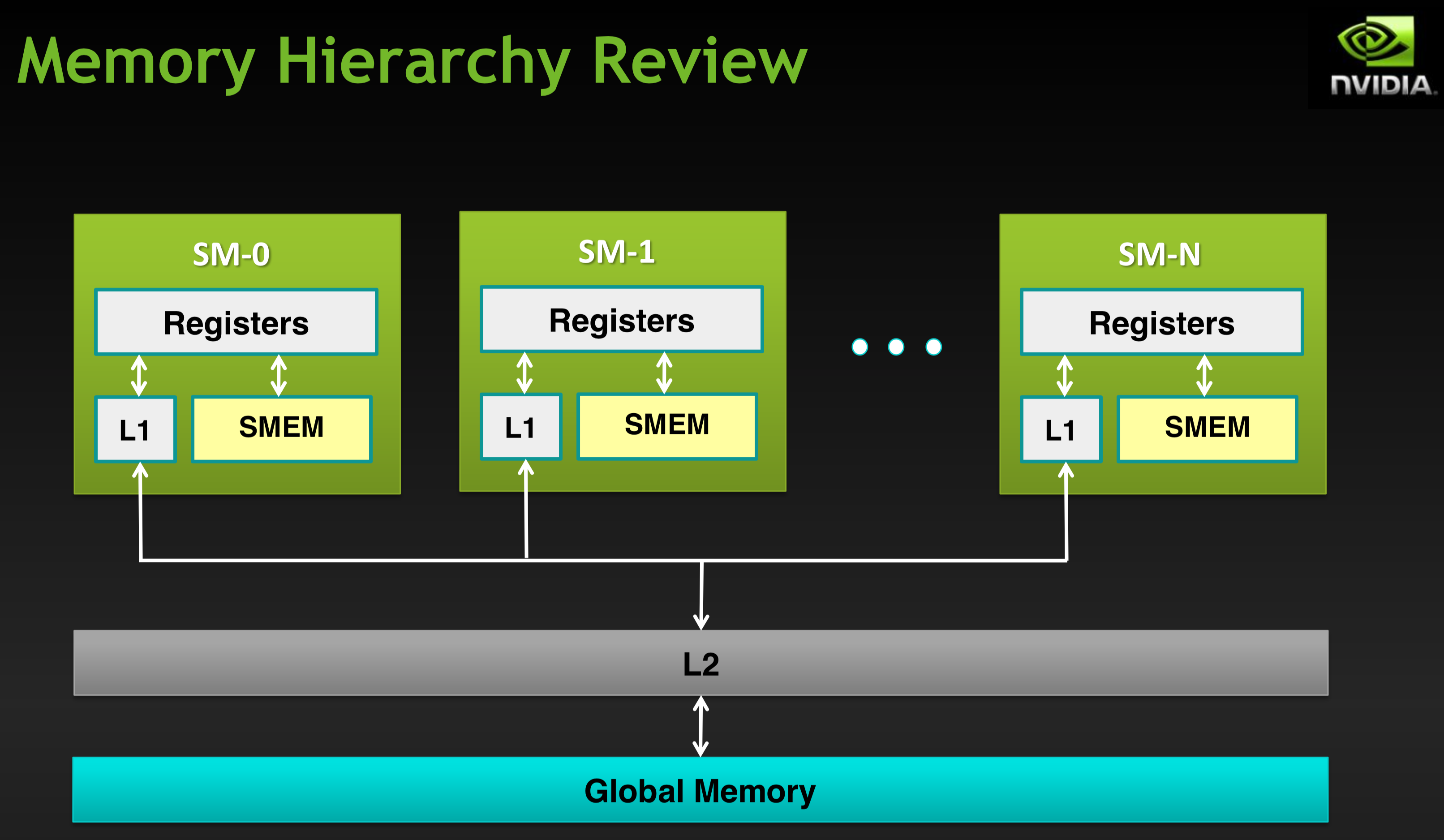
Attempt hit in L1 cache, then L2 cache, then global memory.
Load granularity is 128-byte line.
Memory operations are issued per warp (32 threads) just like instructions (SIMT).
Strive for coalesced memory accesses (warp should access within a contiguous region).
Heterogeneous Programming
The parallel programming in a CUDA program is a mix of C and CUDA. This is called heterogeneous programming. The sequence of instructions can be illustrated by:
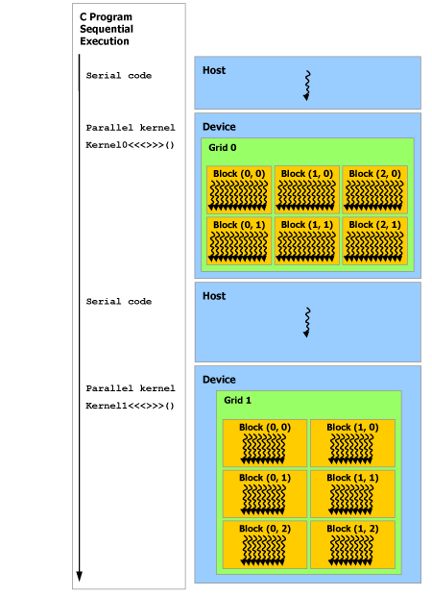
Typical sequence of operations in a CUDA C program
Declare pointers to host and device memory
Allocate memory on host and device
Initialize memory on host
Copy data from host to device memory
Execute one or more kernels that run on the device and operate on device memory
Copy results from device to host memory
Example program
Single-precision A*X plus Y = SAXPY
Example C program (host only)
xint main(void) { int N = 1<<20; float *x, *y, a=2.0f; x = (float*)malloc(N*sizeof(float)); y = (float*)malloc(N*sizeof(float));
for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; }
for(int i = 0; i < N; i++) { y[i] = a*x[i] + y[i]; }
free(x); free(y);}
xxxxxxxxxxvoid saxpy(int n, float a, float *x, float *y) { for(int i = 0; i < n; i++) { y[i] = a*x[i] + y[i]; }}
int main(void) {
int N = 1<<20; float *x, *y, a=2.0f; x = (float)malloc(Nsizeof(float)); y = (float)malloc(Nsizeof(float));
for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; }
saxpy(N,a,x,y); free(x); free(y);}Example CUDA C program (host + device)
xxxxxxxxxx
__global__ void saxpy(int n, float a, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i];}
int main(void) { int N = 1<<20; float *h_x, *h_y, *d_x, *d_y; h_x = (float*)malloc(N*sizeof(float)); h_y = (float*)malloc(N*sizeof(float));
cudaMalloc(&d_x, N*sizeof(float)); cudaMalloc(&d_y, N*sizeof(float));
for (int i = 0; i < N; i++) { h_x[i] = 1.0f; h_y[i] = 2.0f; }
cudaMemcpy(d_x, h_x, N*sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(d_y, h_y, N*sizeof(float), cudaMemcpyHostToDevice);
saxpy<<< (N+255)/256, 256 >>>(N, 2.0f, d_x, d_y); // | blocks | threads | // | in grid | in block | cudaMemcpy(h_y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
float maxError = 0.0f; for (int i = 0; i < N; i++) { maxError = max(maxError, abs(h_y[i]-4.0f)); } printf("Max error: %f\n", maxError); cudaFree(d_x); cudaFree(d_y); free(h_x); free(h_y);}Compile and run the code:
xxxxxxxxxx% nvcc -o saxpy saxpy.cu% ./saxpyMax error: 0.000000
Function execution space specifiers
| Specifier | Use |
|---|---|
__device__ | Execute on device, call from device only |
__global__ | Execute on device, call from host, must be called with an execution configuration <<<gridSize , blockSize>>> |
__host__ | Execute on host, call from host only, this is the default if no specifier is given |
__noinline__ | avoid inlining |
__forceinline__ | force inlining |
xxxxxxxxxx// Define a kernel function.__global__ void saxpy(int n, float a, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i];}
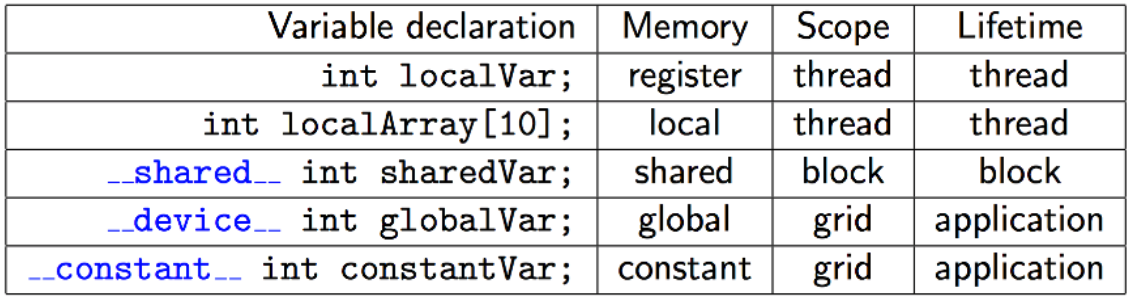
Variable memory space specifiers
| Specifier | Use |
|---|---|
| none | an automatic variable declared in device code without memory space specifiers generally resides in a register |
__device__ | declares device variable in global memory, accessible from all threads, with lifetime of application |
__constant__ | declares device variable in constant memory, accessible from all threads, with lifetime of application |
__shared__ | declares device variable in block's shared memory, accessible from all threads within a block, with lifetime of block |
__restrict__ | standard C definition that pointers are not aliased (so that compiler optimizations may be performed) |
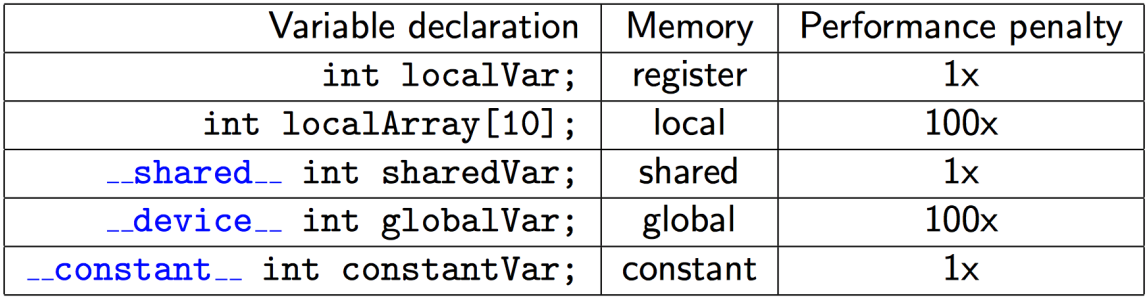
Registers are fastest.
Shared memory can be as fast as a register when there are no bank conflicts or when all threads read from the same address.
Constant memory is cached so it can be fast. Constant memory size is limited.
Global memory is slow. Use coalesced reads and writes. Persistent between kernel calls.
Local memory resides in global memory but can be cached.
Kernel built-in variables
| type | variable | function |
|---|---|---|
| dim3 | gridDim | grid size in blocks: user specified <<< gridDim, … >>> |
| dim3 | blockDim | block size in threads: user specified <<< …, blockDim >>> |
| uint3 | blockIdx | block index within grid: 0, 1, 2, …, gridDim-1 |
| uint3 | threadIdx | thread index within block: 0, 1, 2, ..., blockDim-1 |
| int | warpSize | warp size in threads |
The built-in variables let threads figure out what work they are supposed to do.
xxxxxxxxxx// Define a kernel function.__global__ void saxpy(int n, float a, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i];}
Grid, Blocks, Threads
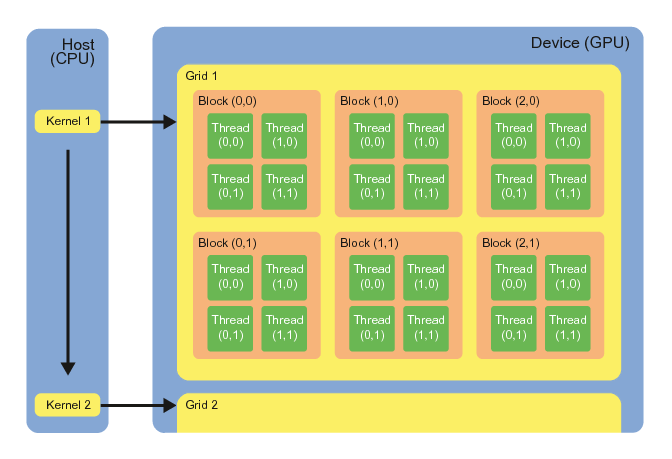
The programmer controls the size and dimensions of grids and blocks when kernels are launched through the execution configuration parameters.
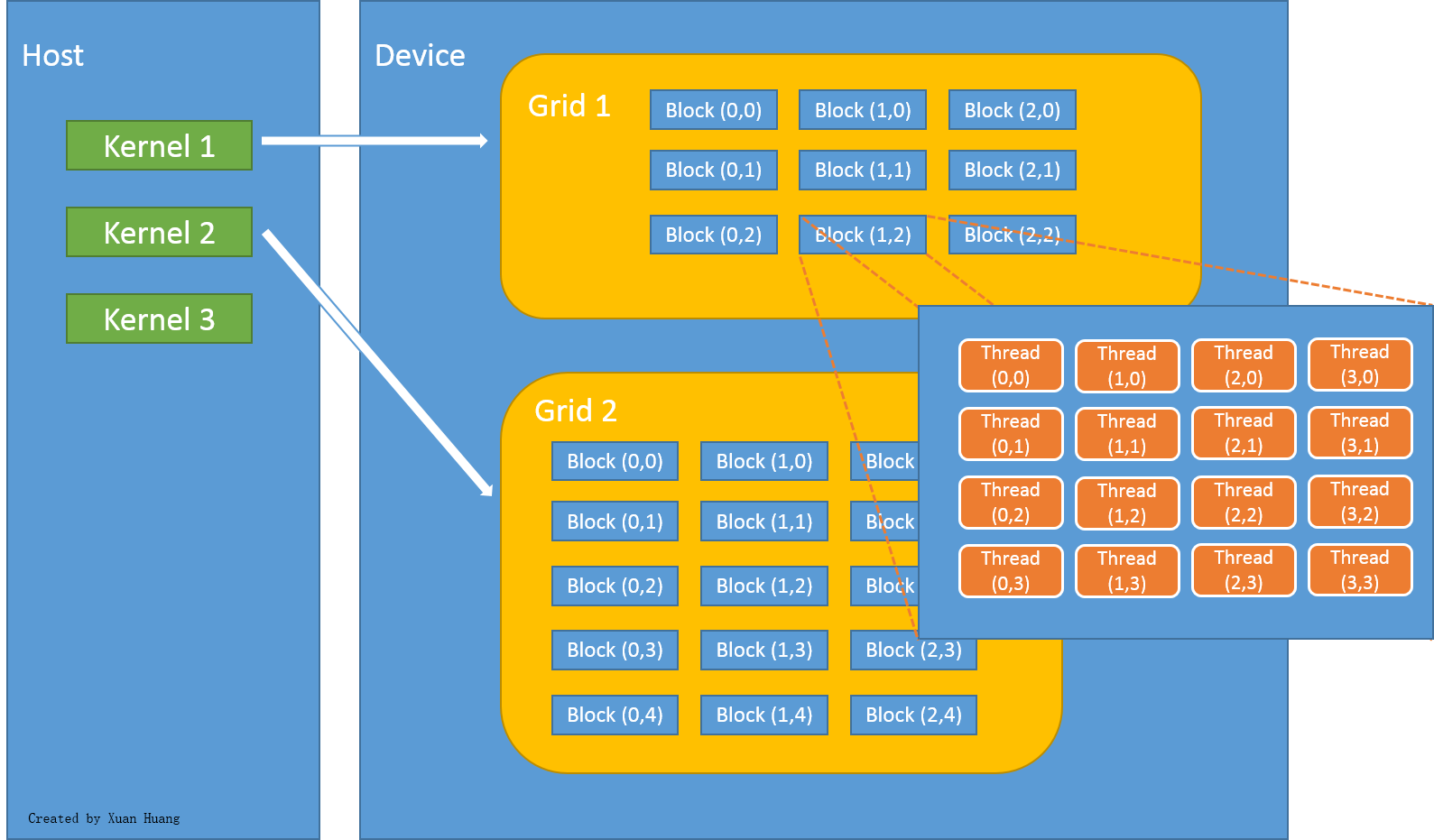
The configuration of the grid, blocks, and threads can be different on each kernel call.
Execution configuration
xxxxxxxxxx__global__ void kernel( ... ) { ... }
dim3 gridSize( nx, ny, nz ); // Grid dimensionsdim3 blockSize( my, my, mz ); // Block dimensions
// Bytes of shared memory dynamically allocated per block// (optional argument that defaults to 0)size_t shmemSize = sizeof(int)*1024;
// Identifier of stream// (optional argument that defaults to 0)cudaStream_t streamId = 0;
kernel<<< gridSize, blockSize, shmemSize, streamId >>>( ... );// |<------- execution configuration -------->|In the SAXPY example, the saxpy kernel was launched using the execution configuration shown below.
xxxxxxxxxx saxpy<<< (N+255)/256, 256 >>>(N, 2.0f, d_x, d_y);This launches
Let
where (N+255)/256 in C.
If
Suppose
On the other hand, if
Splitting up the work
When you have a computational problem to solve, recognize opportunities for parallelization and look for independence in calculations. Map out ways to divide the work among blocks and threads. In the SAXPY example, we decided to create one thread for every element in the arrays: that's 1M threads. We created
Let's look again at our SAXPY kernel and the built-in variables.
xxxxxxxxxx__global__ void saxpy(int n, float a, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i];}
int main( ... ) { ... saxpy<<< 4096 , 256 >>>(N, 2.0f, d_x, d_y); // launch kernel ...}The saxpy kernel launches blockIdx.x built-in variable. Each thread knows which thread it is through the threadIdx.x built-in variable. It also knows the number of blocks through the gridDim.x variable and the number of threads per block through the blockDim.x built-in variable.
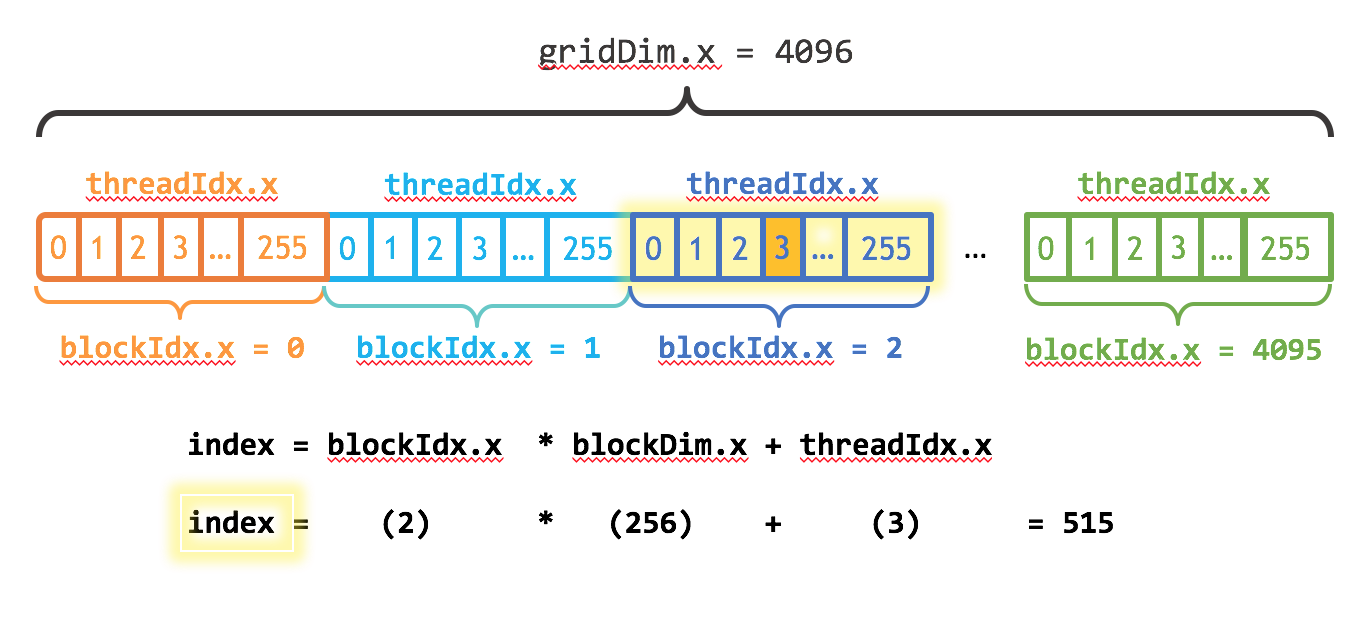
The fourth thread in the third block can compute it's global index (515) and then do work based on that index. Every thread does their own work. No other thread will do the work for index 515.
Synchronization concepts
xxxxxxxxxxcudaMemcpy(d_x, h_x, N*sizeof(float), cudaMemcpyHostToDevice); // synchronous (blocking)cudaMemcpy(d_y, h_y, N*sizeof(float), cudaMemcpyHostToDevice); // synchronous (blocking)
saxpy<<< (N+255)/256, 256 >>>(N, 2.0f, d_x, d_y); // asynchronous (non-blocking)
cudaMemcpy(h_y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost); // synchronous (blocking)Data transfers using cudaMemcpy() are synchronous (blocking): they do not begin until all previously issued CUDA calls have completed, and subsequent CUDA calls can not begin until the synchronous copy has completed.
Kernel launches are asynchronous, control returns immediately to the CPU and does not wait for the kernel to complete.
Timing using CUDA events
xxxxxxxxxx
__global__ void saxpy(int n, float a, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i];}
int main(void) { int N = 1<<20; float *h_x, *h_y, *d_x, *d_y; h_x = (float*)malloc(N*sizeof(float)); h_y = (float*)malloc(N*sizeof(float));
cudaMalloc(&d_x, N*sizeof(float)); cudaMalloc(&d_y, N*sizeof(float));
for (int i = 0; i < N; i++) { h_x[i] = 1.0f; h_y[i] = 2.0f; }
cudaEvent_t start, stop; // <=== cudaEventCreate(&start); // <=== cudaEventCreate(&stop); // <=== cudaMemcpy(d_x, h_x, N*sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(d_y, h_y, N*sizeof(float), cudaMemcpyHostToDevice);
cudaEventRecord(start); // <=== saxpy<<< (N+255)/256 , 256 >>>(N, 2.0f, d_x, d_y); cudaEventRecord(stop); // <=== cudaMemcpy(h_y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
cudaEventSynchronize(stop); // <=== float milliseconds = 0; cudaEventElapsedTime(&milliseconds, start, stop); printf("Elapsed time %f ms\n", milliseconds); cudaFree(d_x); cudaFree(d_y); free(h_x); free(h_y);}cudaEventRecord(…) records the state of the stream at the time of the call but is asynchronous. cudaEventSynchronize(…) waits until the completion of all device work preceding the most recent call to cudaEventRecord(…). cudaEventElapsedTime(…) computes the elapsed time between two events. This will be more accurate than using CPU timers.
Querying device properties
xxxxxxxxxx
int main() { int nDevices;
cudaGetDeviceCount(&nDevices); for (int i = 0; i < nDevices; i++) { cudaDeviceProp prop; cudaGetDeviceProperties(&prop, i); printf("Device Number: %d\n", i); printf(" Device name: %s\n",prop.name); printf(" Memory clock rate (KHz): %d\n",prop.memoryClockRate); printf(" Memory bus width (bits): %d\n",prop.memoryBusWidth); printf(" Compute capability: %d.%d\n",prop.major,prop.minor); printf(" Device is integrated: %d\n",prop.integrated); printf(" 32-bit registers per block: %d\n",prop.regsPerBlock); printf(" Global memory size: %d bytes\n",prop.totalGlobalMem); printf(" Warp size: %d threads\n",prop.warpSize); printf(" Shared memory: %d bytes per block\n",prop.sharedMemPerBlock); }}The cudaDeviceProp structure contains lots of information.
Compute capabilities
Different GPUs have different compute capabilities. You should know the compute capability of your device, its capabilities and limitations.
See Nvidia's Compute Capability Table
Handling CUDA errors
Errors in CUDA C code can arise from:
Errors when CUDA runtime API calls fail
Errors in CUDA kernel calls (e.g. invalid memory access inside a kernel)
All CUDA runtime API calls return an error value. Including explicit error checking code interfers with readability, but it can save hours of debugging. Many people define macros for error checking.
xxxxxxxxxx
__global__ void saxpy(int n, float a, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i];}
int main(void) { int N = 1<<20; float *h_x, *h_y, *d_x, *d_y; h_x = (float*)malloc(N*sizeof(float)); h_y = (float*)malloc(N*sizeof(float));
cudaError_t err; err = cudaMalloc(&d_x, N*sizeof(float)); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); } err = cudaMalloc(&d_y, N*sizeof(float)); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); }
for (int i = 0; i < N; i++) { h_x[i] = 1.0f; h_y[i] = 2.0f; }
cudaEvent_t start, stop; err = cudaEventCreate(&start); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); } err = cudaEventCreate(&stop); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); } err = cudaMemcpy(d_x, h_x, N*sizeof(float), cudaMemcpyHostToDevice); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); } err = cudaMemcpy(d_y, h_y, N*sizeof(float), cudaMemcpyHostToDevice); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); }
err = cudaEventRecord(start); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); }
saxpy<<< (N+255)/256 , 256 >>>(N, 2.0f, d_x, d_y); cudaError_t errSync = cudaGetLastError(); cudaError_t errAsync = cudaDeviceSynchronize(); // Blocks host thread if (errSync != cudaSuccess) fprintf(stderr,"Sync kernel error: %s\n", cudaGetErrorString(errSync)); if (errAsync != cudaSuccess) fprintf(stderr,"Async kernel error: %s\n", cudaGetErrorString(errAsync)); err = cudaEventRecord(stop); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); }
err = cudaMemcpy(h_y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); }
err = cudaEventSynchronize(stop); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); }
float milliseconds = 0; err = cudaEventElapsedTime(&milliseconds, start, stop); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); } printf("Elapsed time %f ms\n", milliseconds); err = cudaFree(d_x); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); } err = cudaFree(d_y); if(cudaSuccess != err) { fprintf(stderr,"%s\n",cudaGetErrorString(err)); } free(h_x); free(h_y);}This code catches the return values from CUDA runtime API calls. If any error occurs, cudaGetErrorString(…) returns a string describing the error.
Errors in kernels can be synchronous or asynchronous. Synchronous errors (such as exceeding the thread count) can be caught by a call to cudaGetLastError(). Asynchronous errors (such as out-of-bounds memory accesses) require a synchronization mechanism. cudaDeviceSynchronize() blocks the host thread until all previously issued commands have completed. Generally this is only used for debugging because it destroys any potential for concurrency.
Profiler nvprof
Nvidia's visual profiler shows the execution timeline.
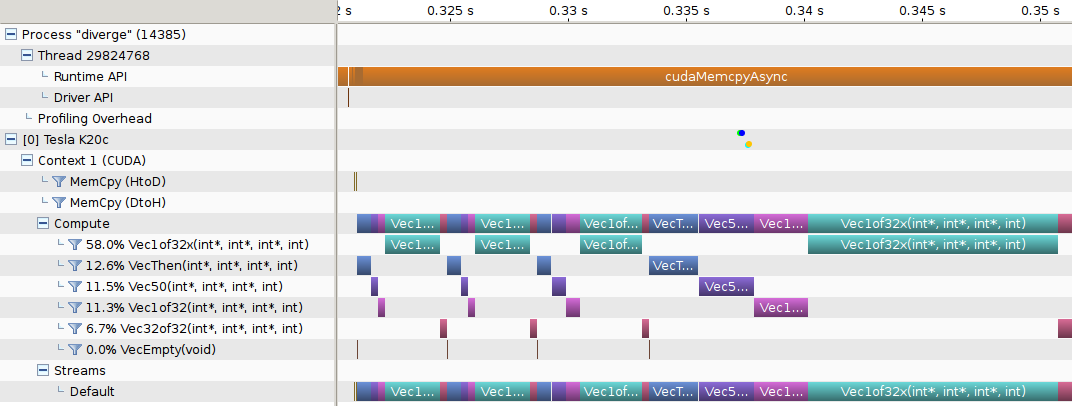
Other Tools in the CUDA SDK
cuda-memcheck detects out of bounds and misaligned memory access errors in CUDA apps. GPU hardware exceptions are also reported. Reports memory leaks.
racecheck reports shared memory data access hazards.
initcheck reports cases where the GPU performs uninitialized access to global memory.
synchcheck reports cases where the application attempts invalid synchronization primitives.
When developing CUDA applications, do the following often:
compile using
nvccrun your app through
cuda-memcheck
Parallel Reduction
Consider the problem of summing the elements of a vector. Such is needed when computing the norm/length of a vector or the inner/dot product between two vectors. Suppose we have a vector of
xxxxxxxxxxfloat sum(float *x, int N) { float s = 0.0f; for(int i = 0; i < N; i++) { s += x[i]; } // sequential sum return s;}
int main(void) { int N = 1<<20; float *x, s; x = (float*)malloc(N*sizeof(float)); // fill array ... // sum array s = sum(x,N); // call host function to sum array
free(x);}
Synchronization functions
void __syncthreads();
waits until all threads in the block have reached this point, and
waits until all global and shared memory accesses are visible to all threads in the block.
Coordinates communication between threads in the same thread block.
Avoid placing __syncthreads(); inside conditional code.
How can parallelism be exploited to efficiently compute the sum? Consider graph below.
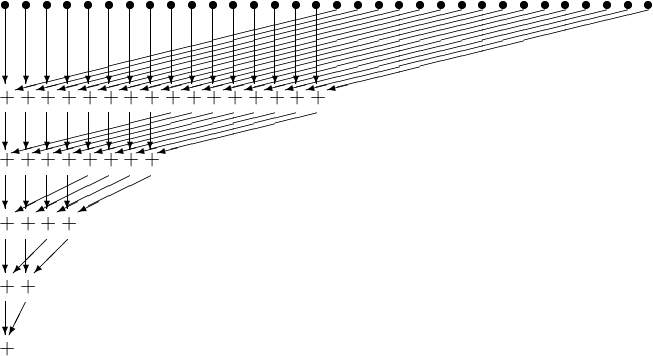
In the first stage,
In the second stage,
In the third stage,
And so on.
If
Write a kernel function to perform parallel dot product.
x
// Parallel dot product programconst int N = 33 * 1024; // array sizeconst int T = 256; // threads per blockconst int B = min( 32, (N+T-1) / T ); // blocks in the grid
__global__ void dot( float *a, float *b, float *c ) { __shared__ float cache[T]; // static allocation (compile time) //extern __shared__ float cache[]; // dynamic allocation (run time) int tid = threadIdx.x + blockIdx.x * blockDim.x;
float temp = 0; while (tid < N) { temp += a[tid] * b[tid]; tid += blockDim.x * gridDim.x; } // set the cache values cache[threadIdx.x] = temp; // synchronize threads in this block __syncthreads();
// for reductions, T must be a power of 2 // because of the following code int i = blockDim.x/2; while (i != 0) { if (threadIdx.x < i) cache[threadIdx.x] += cache[threadIdx.x + i]; __syncthreads(); i /= 2; }
if (threadIdx.x == 0) { c[blockIdx.x] = cache[0]; }}
int main( void ) { float *a, *b, c, *cc; // host variables float *d_a, *d_b, *d_cc; // device variables
// allocate memory on the cpu side a = (float*)malloc( N*sizeof(float) ); b = (float*)malloc( N*sizeof(float) ); cc = (float*)malloc( B*sizeof(float) );
// allocate the memory on the GPU cudaMalloc( (void**)&d_a ,N*sizeof(float) ); cudaMalloc( (void**)&d_b ,N*sizeof(float) ); cudaMalloc( (void**)&d_cc,B*sizeof(float) );
// fill in the host memory with data for (int i=0; i<N; i++) { a[i] = i; b[i] = i*2; }
// copy the arrays 'a' and 'b' to the GPU cudaMemcpy( d_a, a, N*sizeof(float), cudaMemcpyHostToDevice ); cudaMemcpy( d_b, b, N*sizeof(float), cudaMemcpyHostToDevice );
dot<<< B , T >>>( d_a, d_b, d_cc ); // static shared memory allocation // dot<<< B , T , B*sizeof(float) >>>( dev_a, dev_b, dev_partial_c ); // dynamic
// copy the array 'c' back from the GPU to the CPU cudaMemcpy( cc, d_cc, B*sizeof(float), cudaMemcpyDeviceToHost );
// finish up on the CPU side c = 0; for (int i=0; i<B; i++) { c += cc[i]; }
// free memory on the gpu side cudaFree( d_a ); cudaFree( d_b ); cudaFree( d_cc );
// free memory on the cpu side free( a ); free( b ); free( cc );}This example shows how shared memory can be allocated statically and dynamically. It shows how shared memory enables threads in the same block to work together in parallel. It illustrates how thread synchronization may be needed.
Example: Parallel Histogram
How would you create a 256-bin histogram in parallel of a very long list of bytes.
xxxxxxxxxx/* a big number *//* number of bins in histogram */
__global__ void histo_kernel( unsigned char *buffer, long size, unsigned int *histo ) { // clear out the accumulation buffer called temp // since we are launched with 256 threads, it is easy // to clear that memory with one write per thread __shared__ unsigned int temp[NUM_BINS]; temp[threadIdx.x] = 0; __syncthreads();
// calculate the starting index and the offset to the next // block that each thread will be processing int i = threadIdx.x + blockIdx.x * blockDim.x; int stride = blockDim.x * gridDim.x; while (i < size) { // atomic add in shared memory atomicAdd( &temp[buffer[i]], 1 ); i += stride; } // sync the data from the above writes to shared memory // then add the shared memory values to the values from // the other thread blocks using global memory // atomic adds // same as before, since we have 256 threads, updating the // global histogram is just one write per thread! __syncthreads(); atomicAdd( &(histo[threadIdx.x]), temp[threadIdx.x] );}
int main( void ) { unsigned char *buffer = (unsigned char*)big_random_block( SIZE );
// allocate memory on the GPU for the file's data unsigned char *dev_buffer; unsigned int *dev_histo; cudaMalloc( (void**)&dev_buffer, SIZE ); cudaMemcpy( dev_buffer, buffer, SIZE, cudaMemcpyHostToDevice );
cudaMalloc( (void**)&dev_histo, NUM_BINS*sizeof(int) ); cudaMemset( dev_histo, 0, NUM_BINS*sizeof(int) );
// kernel launch - 2x the number of SMs gave best timing cudaDeviceProp prop; cudaGetDeviceProperties( &prop, 0 ); int blocks = prop.multiProcessorCount; histo_kernel<<<blocks*2,NUM_BINS>>>( dev_buffer, SIZE, dev_histo ); unsigned int histo[NUM_BINS]; cudaMemcpy( histo, dev_histo, NUM_BINS*sizeof(int), cudaMemcpyDeviceToHost );
cudaFree( dev_histo ); cudaFree( dev_buffer ); free( buffer ); return 0;}This example introduces a new concept: atomic adds in global and shared memory. There are many other atomic operations. An atomic operation performs three operations:
read a value from memory
operate on the value
write the result back to memory
Because the execution of these operations can not be broken up into small parts without the possibility of errors, it is called an atomic operation. Atomic operations are available for various data types.
| Name | Function |
|---|---|
| atomicAdd() | old = old + val, return old |
| attomicSub() | old = old - val, return old |
| atomicExch() | old = val, return old |
| atomicMin() | old = min(old,val), return old |
| atomicMax() | old = max(old,val), return old |
| atomicInc() | old = ((old >= val) ? 0 : (old+1)), return old |
| atomicDec() | old = (((old == 0) | (old > val)) ? val : (old-1)), return old |
| atomicCAS() | old = (old == compare ? val : old), return old (Compare And Swap) |
| atomicAnd() | old = old & val, return old |
| atomicOr() | old = old | val, return old |
| atomicXor() | old = old ^ val, return old |
Streams
It is possible to execute two or more tasks at once. This is a form of coarse-grained parallelism, in which unrelated processes can execute in parallel. It can be thought of as similar to threads in a multi-core CPU, although with less flexibility. Each task is executed in a stream. The copy engine and the kernel engine can execute one operation at the same time.
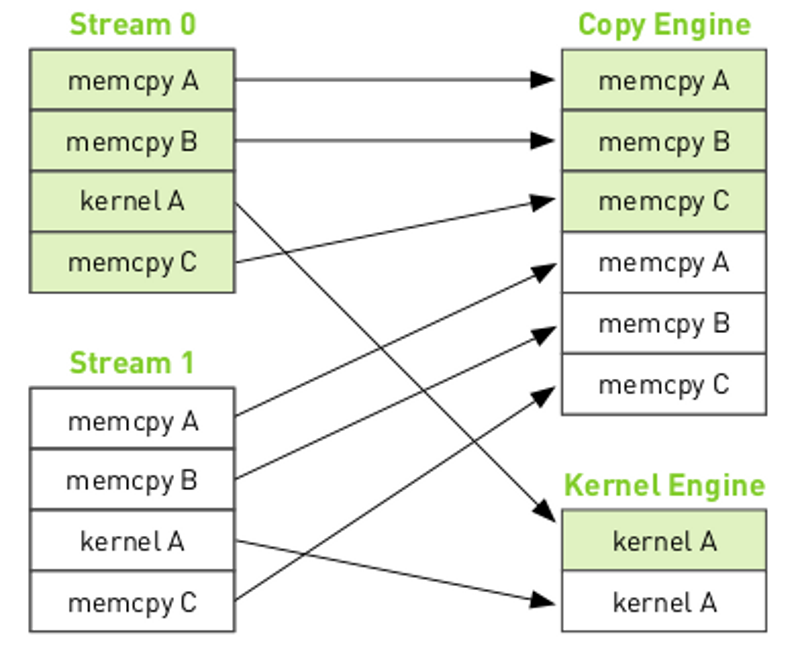
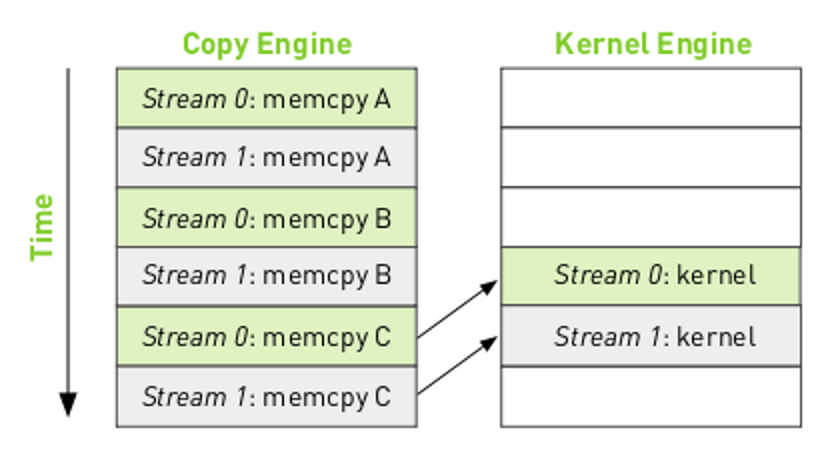
The mapping of the streams onto GPU engines can be shown as:
We can view the call dependency of the different tasks as:
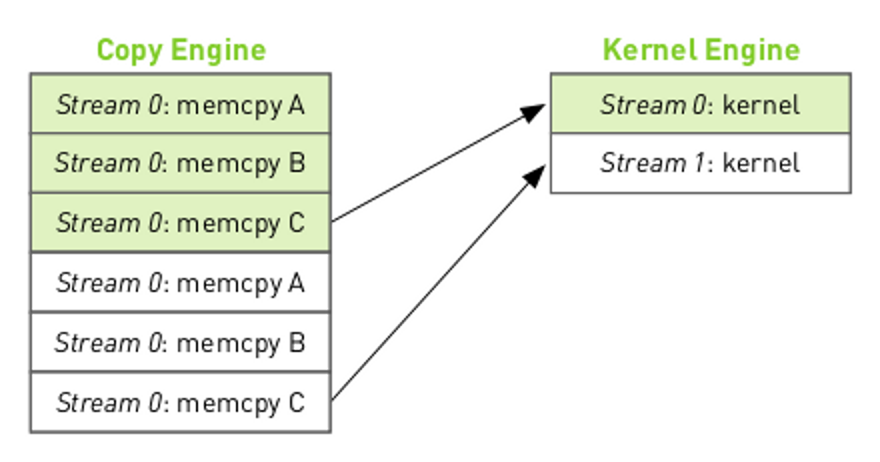
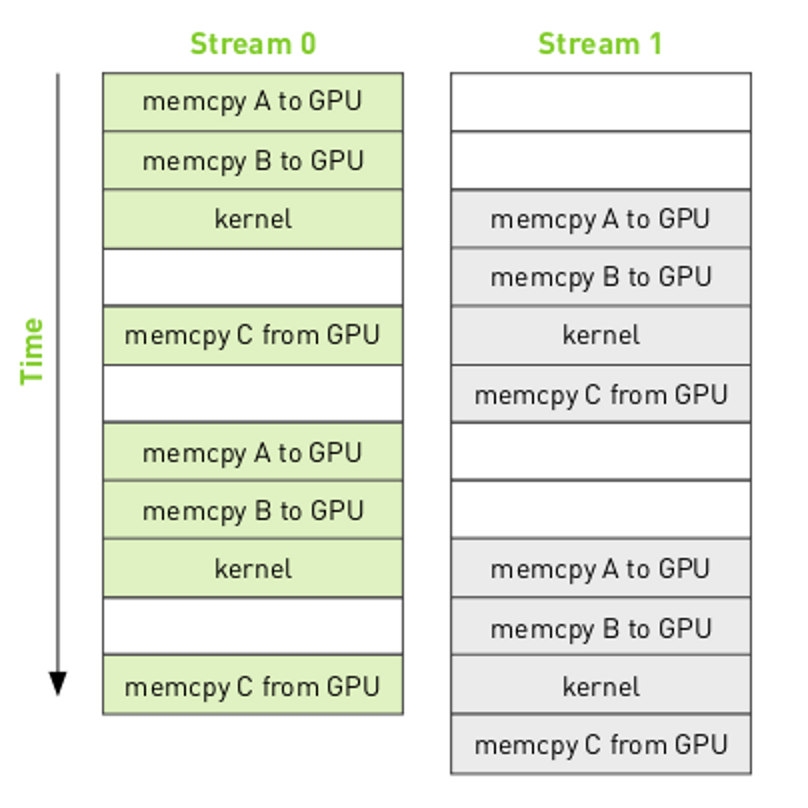
where the arrows indicate that the kernel execution for stream 0 must complete before the memcpy C can start. The resulting execution order will be:
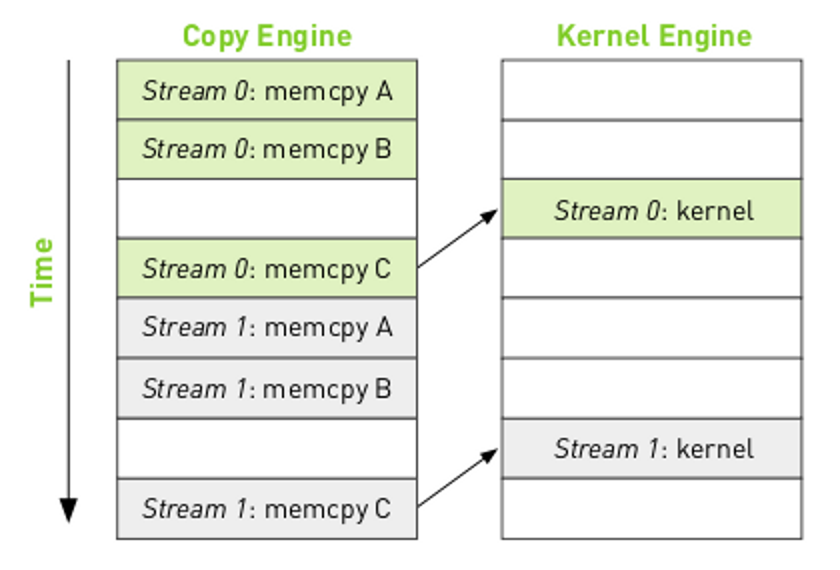
Notice that there are "bubbles" in the execution where the engines are idle. By reordering the operations in the streams it is possible to remove the bubbles.
Important concepts:
Memory must be page-locked (pinned). This keeps the CPU from paging out memory to disk.
Memory transfers are asynchronous.
The stream objects must be allocated and initialized:
cudaStream_t stream0;
HANDLE_ERROR(cudaStreamCreate( &stream0 ));
Kernel launches must include a stream object:
dot<<< B , T , B*sizeof(float), stream0 >>>( dev_a, dev_b, dev_partial_c );
Overlap calls to each stream.
GPU Accelerated Libraries
Challenge problems
RGB to gray conversion
Sobel edge detection